OCUDU India supports offloading CPU-heavy stages of the upper-PHY from the
host to dedicated vRAN accelerators. The goal is better latency and
throughput on the same hardware budget, with the freedom to fall back to
a pure-software path when no accelerator is available.
Design principles
Software parity. The HW and SW paths implement the same interfaces;
no functional difference observable from MAC or above.
Configuration-driven. Choose path via DU YAML at startup. No code
changes, no runtime toggling.
Unified metrics. Every enqueue/dequeue on the HW path emits the
same metric fields the SW path emits. A/B comparisons use one log format.
Batched dispatch. Operations are accumulated per-TB and submitted to
the accelerator as a single burst, amortising DPDK per-call cost.
On-device state. HARQ soft-buffer data stays on the accelerator
between transmissions; the host tracks only context lifecycle.
High-PRB-count cells (80–100 MHz) where software LDPC becomes the
upper-PHY bottleneck.
Multi-cell hosts where freeing CPU on the upper-PHY increases cell
density per server.
Tail-latency-sensitive deployments LDPC decode tail latency
compresses substantially on hardware.
What to read next
First time enabling HWACC? Start with the ACC100 guide
it covers prerequisites, kernel/VFIO setup, YAML, build flags, and a
deployment checklist.
Already running HWACC and want to understand the numbers? Jump to the
benchmark results for the A/B comparison.
Adding a new accelerator backend? See the
contributing guide for how to file an RFC.
1 - Intel ACC100 LDPC offload
Offload LDPC encoding (PDSCH) and decoding (PUSCH) to Intel ACC100 vRAN accelerator cards via DPDK BBDEV, with full upper-PHY metrics instrumentation for side-by-side comparison with the software-AVX-512 path.
Scope: hardware-accelerated LDPC encoding (PDSCH) and decoding (PUSCH)
on Intel ACC100 vRAN accelerator cards, with full upper-PHY metrics
instrumentation so operators can directly compare CPU-software and
HW-offload performance in production logs.
Introduced in commit:aa6db7d066
Highlights
LDPC offload for both PDSCH and PUSCH the most CPU-heavy channel-coding
steps move off the host and onto the accelerator.
Configuration-driven enable or disable via the DU YAML; no code changes.
Unified metrics the same per-block PHY metric fields populate whether
LDPC runs in software (AVX-512) or on the accelerator, enabling direct
side-by-side comparison from one log format.
Measured gains on real traffic significantly lower PUSCH decode
latency, tighter tail latency, higher processor throughput, and reduced
upper-PHY uplink CPU (see §7).
1. Prerequisites
1.1 Hardware
Intel ACC100 PCIe card, SR-IOV capable; at least one VF exposed to the host.
x86-64 CPU with AVX2 (AVX-512 recommended for the software-fallback path).
≥ 2 GB of 2 MiB hugepages.
PCIe slot on the same NUMA node as the upper-PHY worker cores.
1.2 Software
Component
Minimum version
Notes
DPDK
22.11
Tested with 25.11; ACC100 PMD (baseband_acc) required.
# Kernel boot parameters (then update-grub + reboot):intel_iommu=on iommu=pt hugepagesz=2M hugepages=1024# Hugepage mount if not done by distro:echo1024| sudo tee /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
# Load VFIO modules:sudo modprobe vfio-pci
echo1| sudo tee /sys/module/vfio_pci/parameters/enable_sriov # if kernel-builtin# Create one SR-IOV VF and bind it to vfio-pci:echo1| sudo tee /sys/bus/pci/devices/<ACC100_PF_BDF>/sriov_numvfs
sudo dpdk-devbind.py --bind=vfio-pci <ACC100_VF_BDF>
# Start pf_bb_config holding the PF group open with a VF token.# The token (UUID) is required in the DU's EAL args.sudo /opt/pf-bb-config/pf_bb_config ACC100 \
-c /opt/pf-bb-config/acc100/acc100_config_vf_5g.cfg \
-v <UUID> &
After setup, dpdk-test-bbdev should enumerate the VF as intel_acc100_vf.
2. Architecture overview
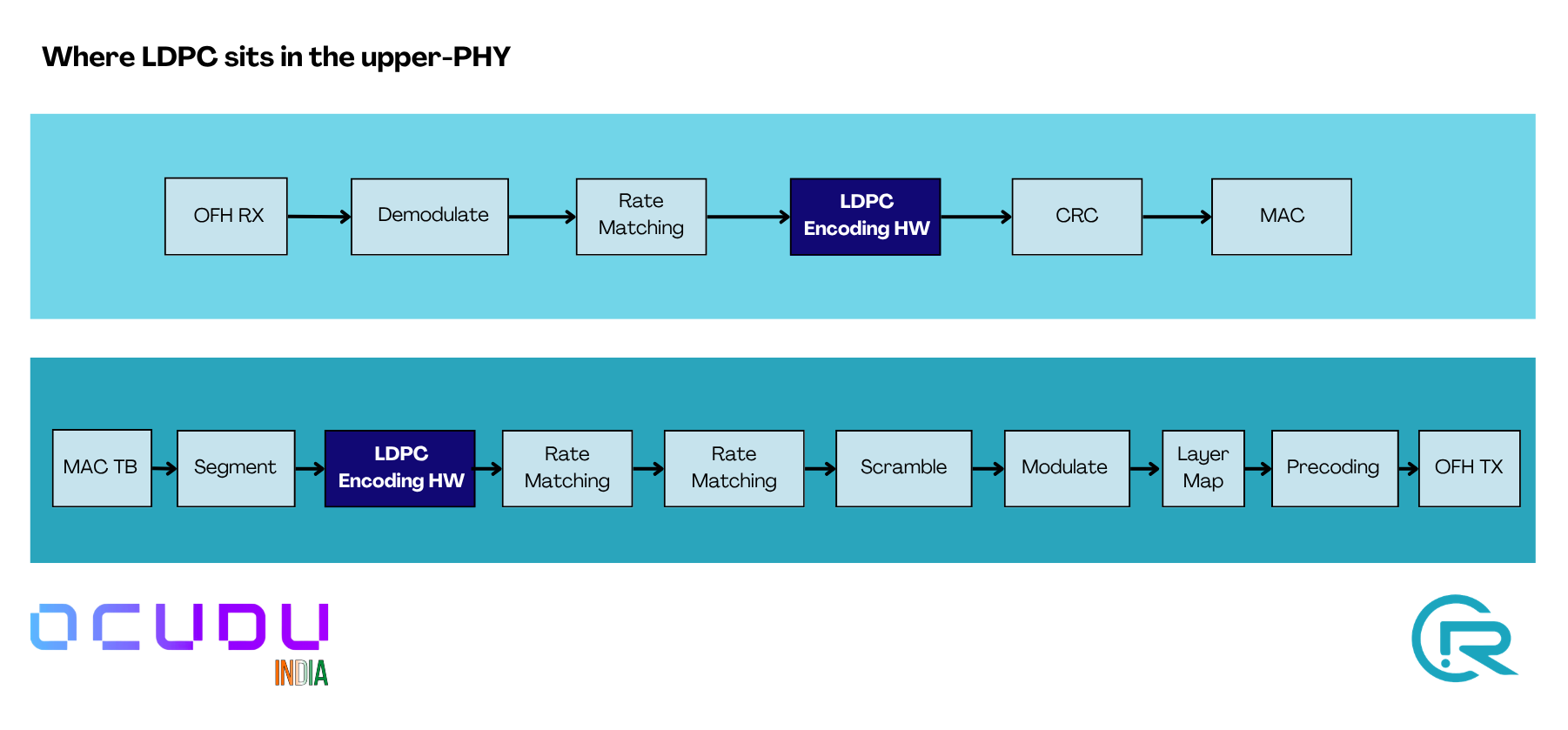
2.1 Where LDPC sits in the upper-PHY
LDPC encode (PDSCH) and LDPC decode (PUSCH) are the two steps this
feature accelerates. On the software path they are AVX2/AVX-512 kernels; on
the HW path they become batched DPDK BBDEV operations dispatched to the
ACC100. Everything else in the chain stays on the CPU.
UL and DL pipelines through the upper-PHY. The LDPC stages (dark blue) run on the ACC100; all other stages stay on CPU.
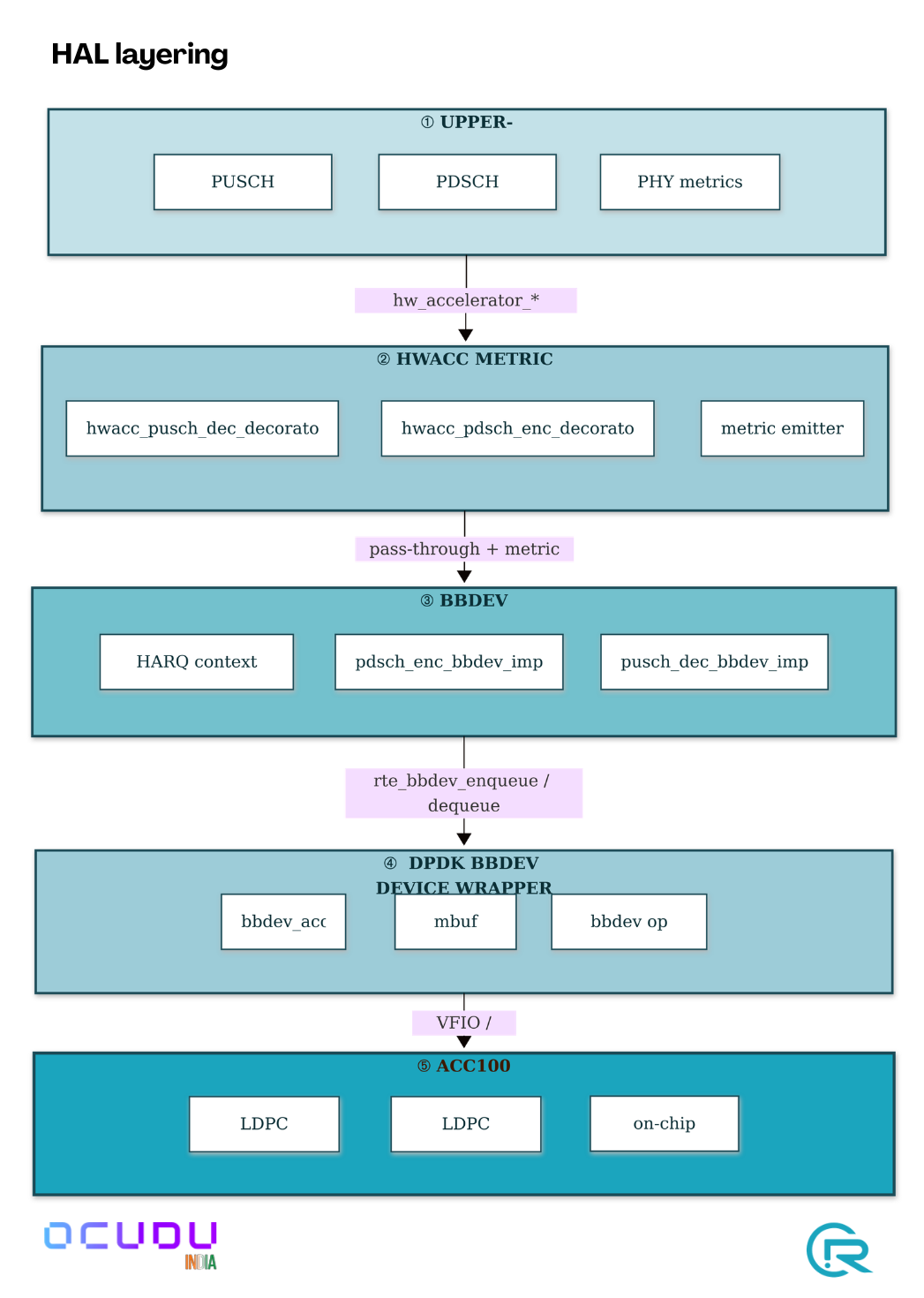
2.2 HAL layering
The upper-PHY factory checks for a hardware accelerator factory at
construction. If present, the HW path is built; otherwise the software
AVX-512 path is used. The choice is made once at startup from the YAML
there is no runtime toggling.
Five-layer HAL from the upper-PHY down to the ACC100 silicon. Each layer's interface to the one below is labelled.
3. Implementation summary
The integration is implemented as a hardware-abstraction layer that plugs
into the existing upper-PHY factory pattern. Four things are worth knowing:
Batching. Encode and decode ops are accumulated in a per-instance
buffer and submitted to the accelerator as a single burst on the first
dequeue call of each transport block. This amortises the DPDK per-call
cost across all code blocks of the TB.
Shared pools. The HAL factory owns one set of DPDK mbuf and op
mempools for all encoder and decoder instances the upper-PHY creates.
Pool size scales automatically with the total queue count across
allowlisted accelerators.
On-chip HARQ. Soft data for HARQ combining stays on the accelerator
between transmissions, addressed by a CB-indexed offset. The host tracks
only the lifecycle of each context entry, not the soft data itself.
Unified metrics. A thin decorator wraps the HW accelerator interface,
times each enqueue–dequeue pair, and emits the same metric events the
software path does. The existing upper-PHY aggregator consumes both
sources transparently.
A handful of ACC100 silicon quirks are handled internally by the HAL (input
byte-alignment, a single-CB transport-block special case, a per-op E-limit
guard, a long-session HARQ-context wrap-around). These require no action
from the operator.
4. Configuration
Enable ACC100 offload in the DU YAML:
hal:eal_args:"--lcores (0-1)@(0-17) --file-prefix=ocudu_gnb --no-telemetry
-a <OFH_NIC_VF_BDF>
-a <ACC100_VF_BDF>
--vfio-vf-token=<PF_BB_CONFIG_UUID>
--iova-mode=pa"bbdev_hwacc:hwacc_type:"acc100"id:0pdsch_enc:nof_hwacc:4cb_mode:truededicated_queue:truepusch_dec:nof_hwacc:4force_local_harq:falsededicated_queue:true
Notes:
nof_hwacc for single-cell deployments, 2–4 is sufficient; for
multi-cell or heavy-load setups, 8–16. Setting higher than the
upper-PHY’s concurrency limits is wasteful.
--iova-mode=pa is recommended; the va mode is known to interact
poorly with some NIC drivers in DPDK 25.11.
The VFIO-VF token must match the UUID passed to pf_bb_config -v.
If pf_bb_config is restarted, update the YAML.
Warning: the configured maximum PDSCH concurrency ... is overridden by the
number of PDSCH encoder hardware accelerated functions (N)
Warning: the configured maximum PUSCH and SRS concurrency ... is overridden
by the number of PUSCH decoder hardware accelerated functions (N)
The same fields populate for both the CPU-software and ACC100-HW paths,
enabling side-by-side A/B comparison from a single log format.
7. Results
7.1 Test environment
Item
Value
Host
Single-socket x86_64, 18 cores, AVX-512 capable
OS / DPDK
Linux 5.15 / DPDK 25.11
pf_bb_config
24.03
ACC100
1 PF + 1 VF bound to vfio-pci
OFH NIC
iavf VF for 7.2-split RU
UE workload
Real UE + iperf3 DL/UL + 2 min video streaming + 2 speed tests
Cell
100 MHz TDD, 30 kHz SCS, 4T4R, band n78, 256-QAM max
All measurements taken with the same physical UE and RU; only the gNB
binary differs between the two rows (AVX-512 vs ACC100).
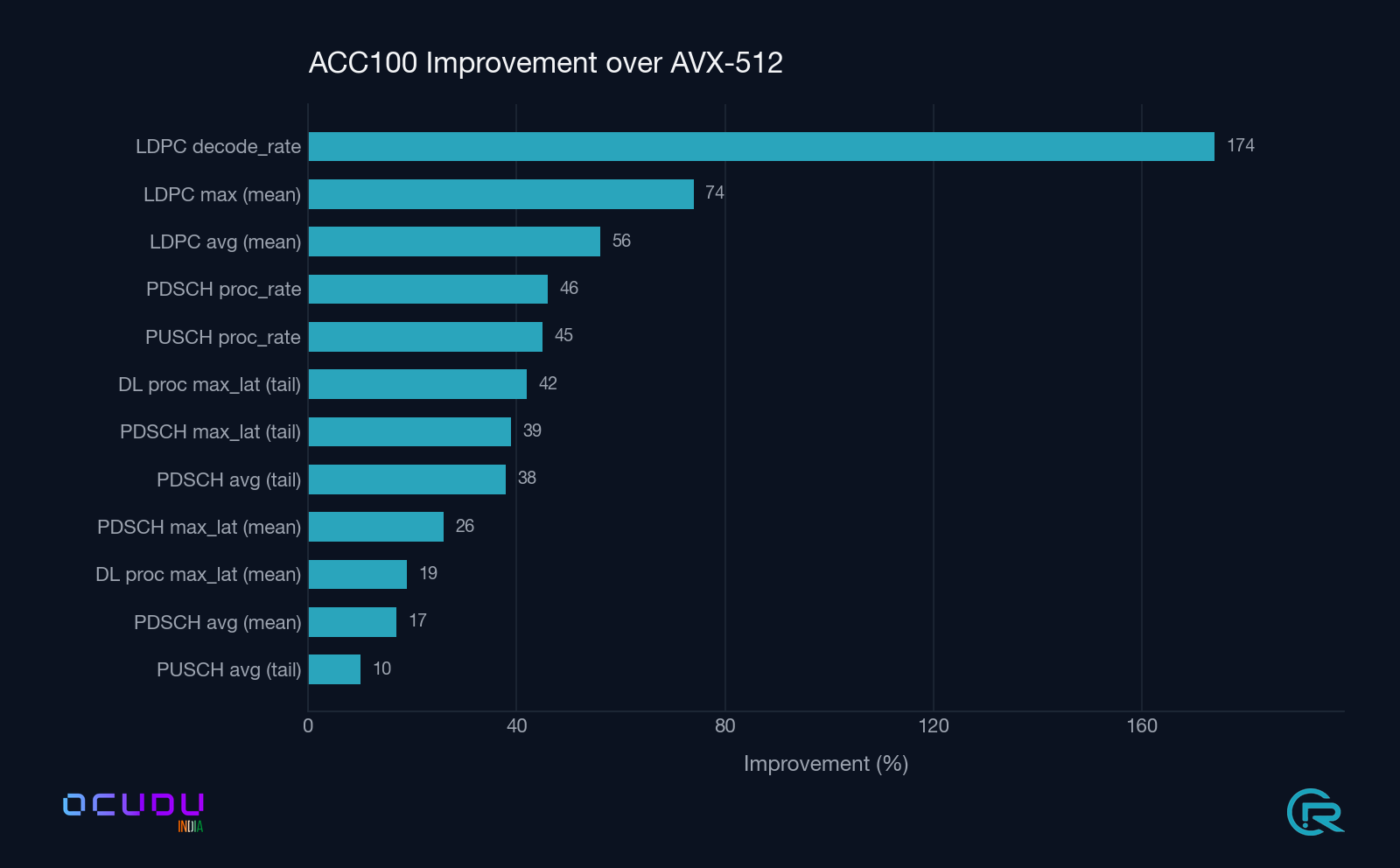
Summary ACC100 percentage improvement over AVX-512 across all measured upper-PHY metrics. LDPC decode throughput leads the board at +174 %.
7.2 End-to-end upper-PHY A/B
Mean / max over ~175 one-second metric windows each.
Metric
AVX-512 (mean / max)
ACC100 (mean / max)
ACC100 Δ
DL processing max_latency
114.9 / 330.2 µs
99.7 / 206.4 µs
−13 % mean, −37 % tail
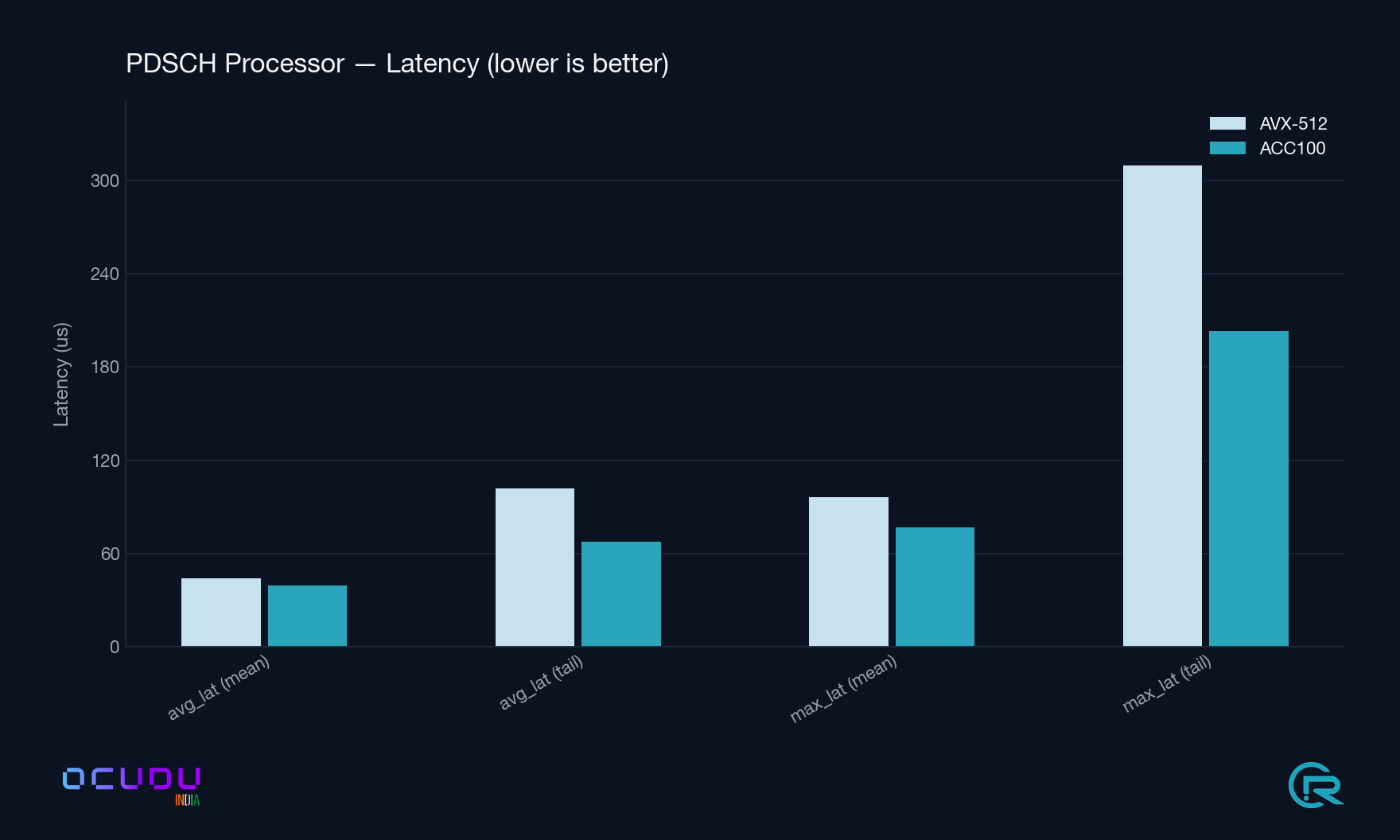
PDSCH Processor avg_latency
44.0 / 101.7 µs
39.3 / 67.8 µs
−11 % mean, −33 % tail
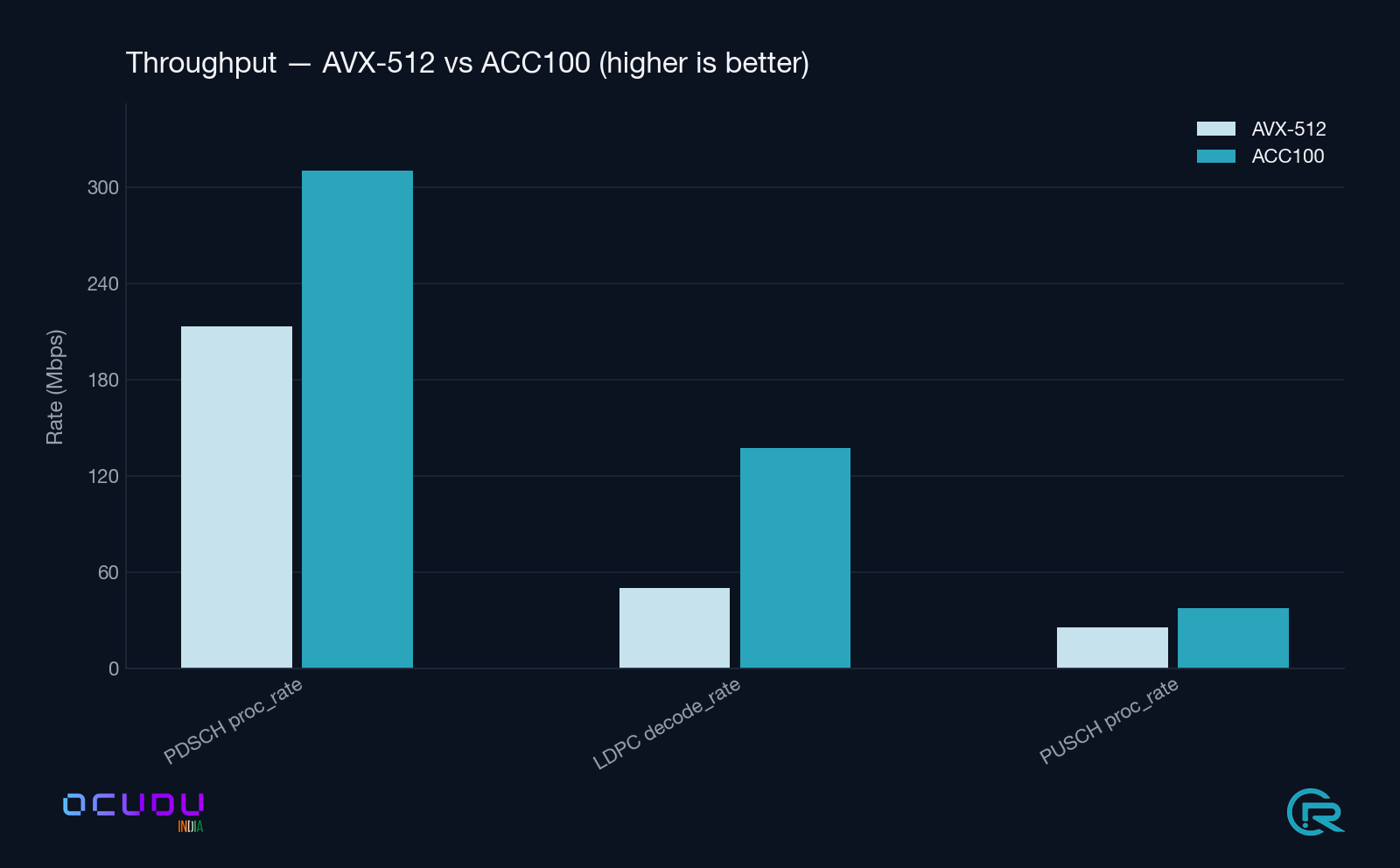
PDSCH Processor proc_rate
198.0 Mbps
310.1 Mbps
+57 %
PDSCH Processor max_latency
96.5 / 309.8 µs
76.6 / 203.2 µs
−21 % mean, −34 % tail
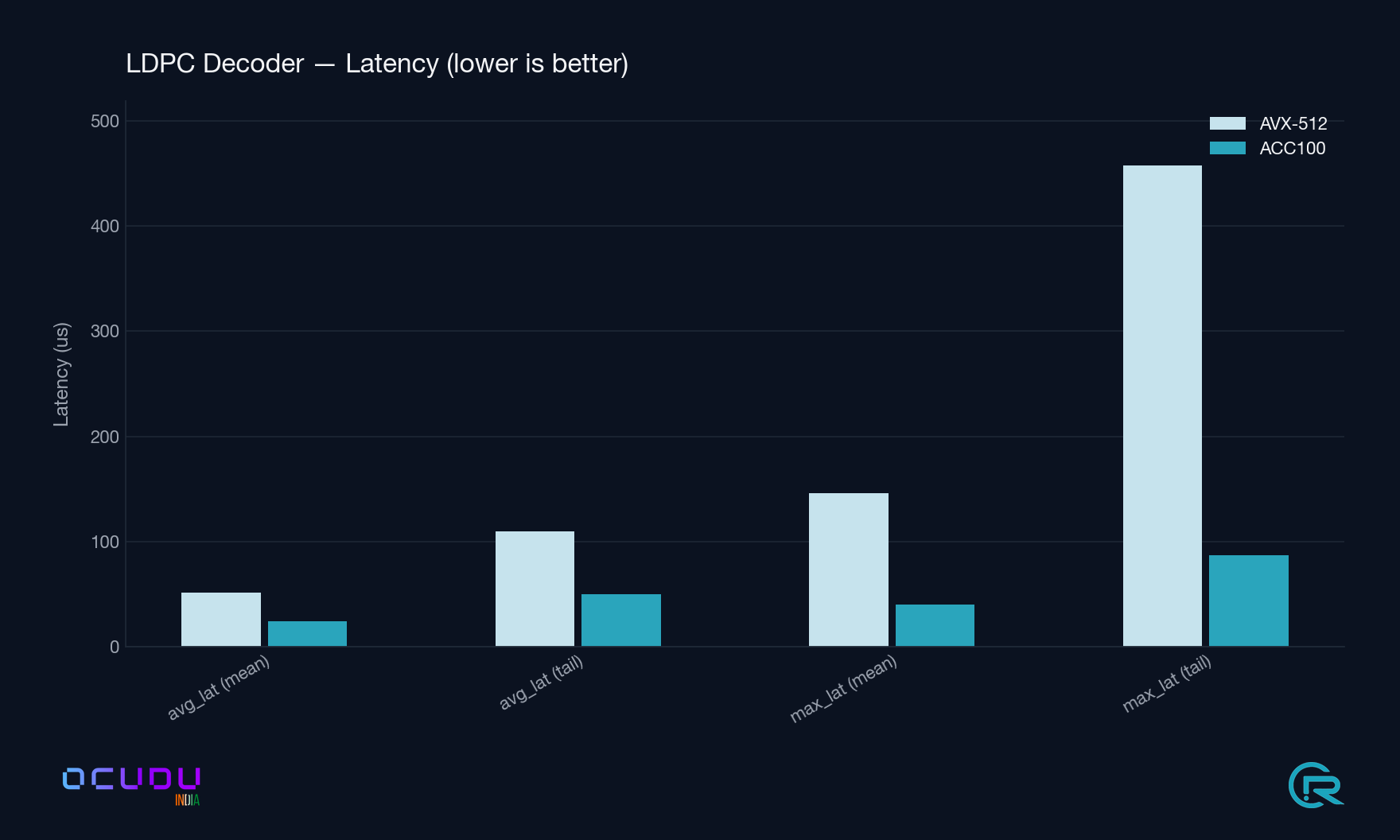
LDPC Decoder avg_latency
51.6 / 109.4 µs
24.5 / 50.1 µs
−53 % (2.1× faster)
LDPC Decoder max_latency
145.9 / 457.7 µs
40.5 / 86.7 µs
−72 % (3.6× better tails)
LDPC Decoder decode_rate
46.6 Mbps
137.4 Mbps
+195 % (2.9×)
PUSCH Processor avg_data_latency
231.9 / 761.5 µs
246.3 / 736.4 µs
+6 % mean, −3 % tail
PUSCH Processor proc_rate
24.0 Mbps
37.4 Mbps
+56 %
LDPC Decoder latency lower is better. The tail-latency gap (rightmost pair) is the headline: 3.6× tighter under ACC100.PDSCH Processor latency lower is better. Tail latency compresses by roughly one third.Throughput higher is better. LDPC decode rate nearly triples; PDSCH and PUSCH processor rates both rise by about half.
7.3 CPU utilisation
Metric
AVX-512 (mean / max)
ACC100 (mean / max)
upper_phy_dl
3.63 % / 22.7 %
4.92 % / 33.9 %
upper_phy_ul
3.79 % / 28.9 %
2.36 % / 15.4 % (−38 %)
ldpc_rm (rate match)
1.30 % / 10.9 %
0.00 % (on accelerator)
ldpc_rdm (rate dematch)
0.13 % / 1.0 %
0.00 % (on accelerator)
The uplink CPU reduction is the headline operational benefit: one core is
freed on the upper-PHY under sustained traffic, allowing either higher
cell counts on the same host or tighter scheduling-latency budgets.
Note on the DL rows. The per-CB ldpc_encoder_* fields on the HW
path reflect batch wall-clock time rather than serialised per-CB compute
time, because ops are submitted to the accelerator in bursts. Use the
PDSCH Processor rows and upper_phy_dl for apples-to-apples DL
comparison those are measured once per TB and are directly comparable.
8. Deployment checklist
Install or confirm DPDK ≥ 22.11 with ACC100 PMD.
Confirm pf_bb_config daemon is running; note its VFIO-VF token.
Bind the ACC100 VF(s) to vfio-pci.
Add the hal.bbdev_hwacc block to the DU YAML (see §4).
Build with ENABLE_PDSCH_HWACC=True and ENABLE_PUSCH_HWACC=True (see §5).
Verify startup log shows intel_acc100_vf and ldpc_enc_q=N ldpc_dec_q=N.
Enable metrics.layers.enable_du_low to observe the per-component LDPC metrics (§6).