
7 minute read
Modern vRAN systems are steadily transitioning toward heterogeneous compute, where general-purpose CPUs are augmented with domain-specific accelerators to meet strict real-time PHY requirements.
PRACH detection is a timing-critical, bursty L1 function - correlating received samples against up to 64 Zadoff-Chu preambles, computing IDFTs, accumulating per-shift power, and returning the peak. It competes for the same upper-PHY CPU cores that everything else needs.
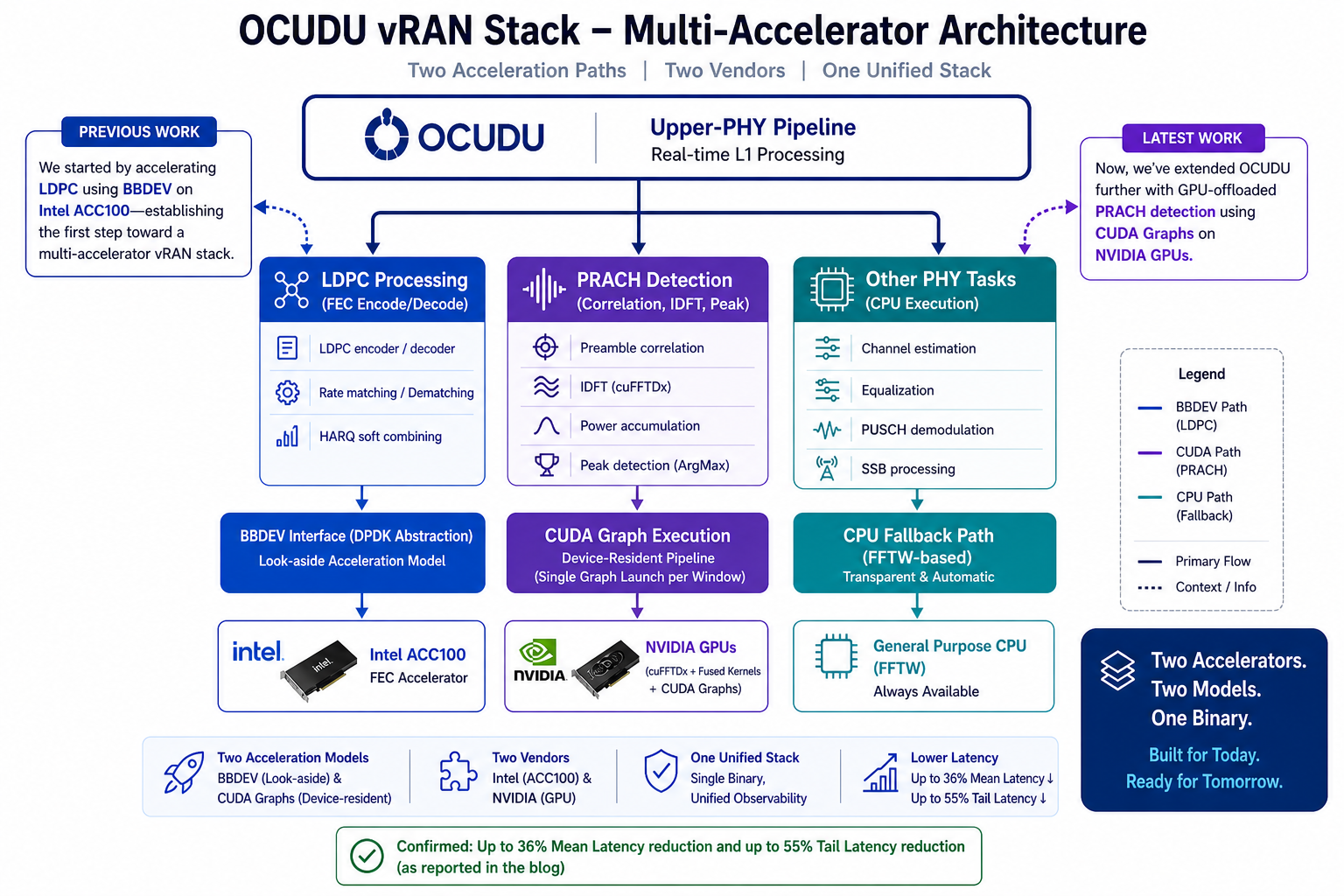
After our BBDEV-based LDPC offload demonstrated on Intel ACC100, we are extending OCUDU’s upper-PHY pipeline with a second hardware-acceleration path - this time targeting PRACH detection, executed as a single CUDA graph on an NVIDIA GPU, with the IDFT running device-side via cuFFTDx. Two acceleration paths, two vendors, one binary.
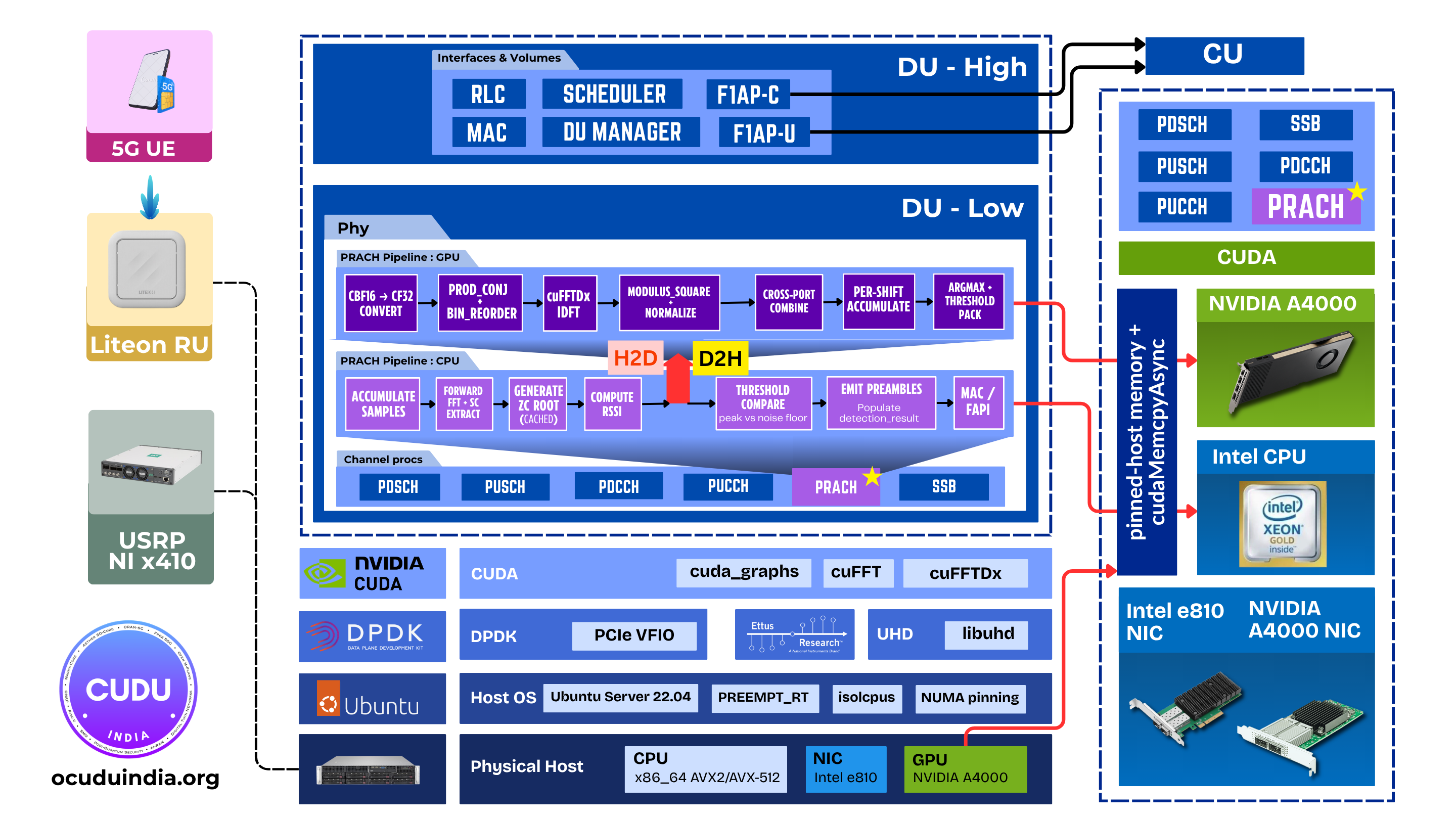
Architecture Overview
The integration follows the same architectural discipline as the
BBDEV LDPC offload: a strict separation between detection logic and
backend implementation. Runtime backend selection via the
OCUDU_PRACH_DFT_BACKEND environment variable, transparent CPU-FFTW
fallback when no CUDA device is present, and unified observability
across paths.
Execution Pipeline
The full PRACH detection chain is captured into one
cudaGraphExec_t. Hot-path cost per detection window is one
cudaGraphLaunch + cudaStreamSynchronize.
- H2D transfer of the cbf16 PRACH buffer (only host-to-device traffic per window)
- Fused conjugate-product correlation + bin reorder + cuFFTDx IDFT + power normalization - one device kernel, no intermediate device-memory traffic
- Non-coherent cross-port combine, per-shift accumulation, CUB ArgMax for peak detection
- D2H transfer of the result (~1 KB per detection window)
Everything between H2D and D2H stays device-resident. No host round-trips between stages.
Implementation Highlights
cuFFTDx Fused Kernel
For the standard PRACH IDFT sizes - 256-point (short format) and 1024-point (long format) - a single cuFFTDx device kernel fuses correlation, bin reorder, IDFT, and power normalization into one launch. The IDFT becomes part of the kernel rather than a library call between kernels, eliminating host synchronization and intermediate staging.
CUDA-Graph Execution
Capturing the full pipeline as a static CUDA graph eliminates per-stage host launch overhead and host-side scheduling jitter - both of which matter more than peak FLOPs for a workload of this size. First-window graph build cost (~3.5–5 ms) is paid once at gNB startup, before any UE can transmit PRACH.
Zero-Allocation Hot Path
All device and pinned-host buffers are pre-allocated at construction
for worst-case dimensions (64 ports × 12 symbols). detect()
touches no allocator.
Single-Binary, Drop-In
Same as the LDPC path: backend selection by configuration, not code. One binary supports both GPU and CPU detectors. A/B benchmarking under identical runtime conditions is a matter of restarting the gNB.
Observability
Metric symmetry was a hard requirement. GPU and CPU detectors emit
identical counters: detects, mean / min / max latency. The GPU
detector adds graph_builds and cached_graphs to confirm the
graph cache is behaving as expected.
During GPU operation, the CPU fallback detector remains constructed
but reports detects=0 - a useful invariant. Any non-zero value
flags a config path that routed back to CPU. No dashboards, logging
pipelines, or benchmarking frameworks need to change between paths.
GPU Performance Benchmark
Before head-to-head comparison against the CPU detector, we characterized the GPU path on its own to understand how it behaves under load and how much headroom it leaves against the PRACH timing budget.
To stress the detector beyond what a single live cell ever sees, the
benchmark sweeps nof_rx_ports from 1 up to 64 with the full
64-preamble sweep (the worst-case detection load: every Zadoff-Chu
sequence correlated against every received port-symbol). Both formats
are tested - long format (1.25 kHz SCS, DFT=1024, 800 µs window)
and short format (B4, 30 kHz SCS, DFT=256). All numbers below are
measured on NVIDIA RTX A4000 with 1000 repetitions per
configuration.
Long format - full 64-preamble sweep
| Ports | CPU (FFTW) median | GPU (cuFFTDx) median | Speedup | CPU 99p tail | GPU 99p tail |
|---|---|---|---|---|---|
| 1 | 291 µs | 63 µs | 4.6× | 294 µs | 65 µs |
| 2 | 423 µs | 55 µs | 7.6× | 425 µs | 56 µs |
| 4 | 664 µs | 64 µs | 10.4× | 666 µs | 66 µs |
| 8 | 1 216 µs | 66 µs | 18.6× | 1 220 µs | 75 µs |
| 16 | 2 190 µs | 81 µs | 27.1× | 2 196 µs | 90 µs |
| 32 | 4 161 µs | 121 µs | 34.5× | 4 169 µs | 128 µs |
| 64 | 8 190 µs | 188 µs | 43.5× | 8 205 µs | 197 µs |
At 64 ports the CPU FFTW detector runs 8.2 ms per detection window - well past the PRACH timing budget. The GPU finishes the same workload in 188 µs median, 197 µs at the 99th percentile.
Short format (B4) - full 64-preamble sweep
| Ports | CPU (FFTW) median | GPU (cuFFTDx) median | Speedup | CPU 99p tail | GPU 99p tail |
|---|---|---|---|---|---|
| 1 | 96 µs | 61 µs | 1.6× | 98 µs | 63 µs |
| 2 | 163 µs | 123 µs | 1.3× | 166 µs | 136 µs |
| 4 | 292 µs | 124 µs | 2.4× | 298 µs | 135 µs |
| 8 | 578 µs | 134 µs | 4.3× | 581 µs | 142 µs |
| 16 | 1 114 µs | 142 µs | 7.8× | 1 118 µs | 159 µs |
| 32 | 2 192 µs | 172 µs | 12.8× | 2 197 µs | 182 µs |
| 64 | 4 337 µs | 219 µs | 19.8× | 4 345 µs | 238 µs |
What the numbers say
- The CPU path scales linearly with port count. Every doubling of ports roughly doubles CPU detect time. At 64 ports the long-format detector takes 8.2 ms - more than 8× the entire PRACH window budget. There is no production cell config where this is viable.
- The GPU path scales sub-linearly. Going from 1 to 64 ports multiplies GPU detect time by ~3× (long format) or ~3.6× (short format), versus the CPU’s 28-45× scaling. The fused cuFFTDx kernel amortises bin reorder, IDFT, and power normalisation over a single device launch - more ports means a larger batch, not more launches.
- GPU tail latency stays tight. At every port count, the GPU 99-percentile is within ~10 % of the median. CPU 99p sits within 1 % of the median (FFTW is deterministic) but the absolute number is the problem - 8.2 ms can’t be hidden by lucky tails.
- Short format gets less of a win at low port counts. At
p=1short format the GPU is only 1.6× faster - here CPU FFTW is already very fast (~96 µs) and PCIe + graph launch overhead dominates GPU runtime. As port count grows the GPU takes over decisively.
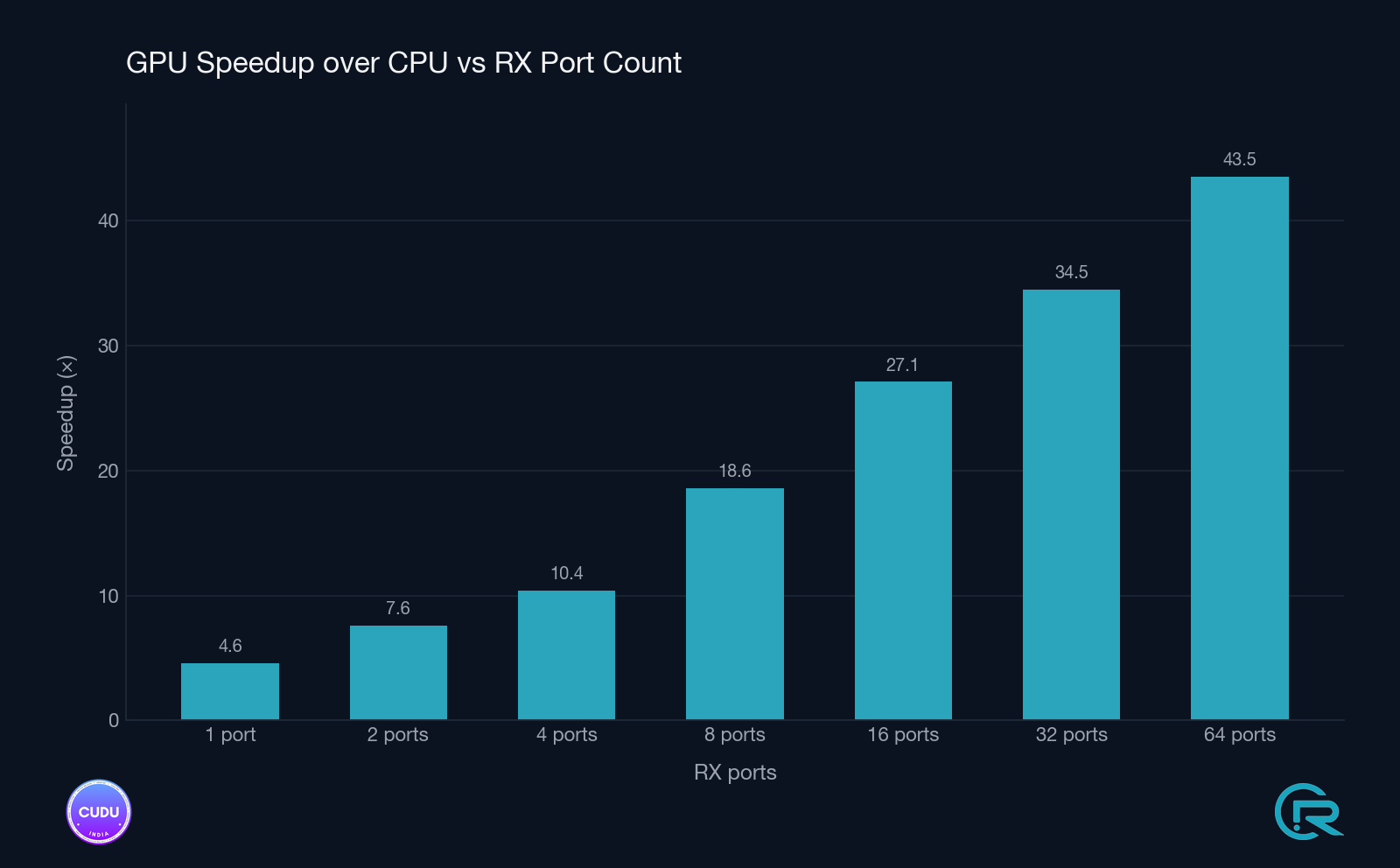
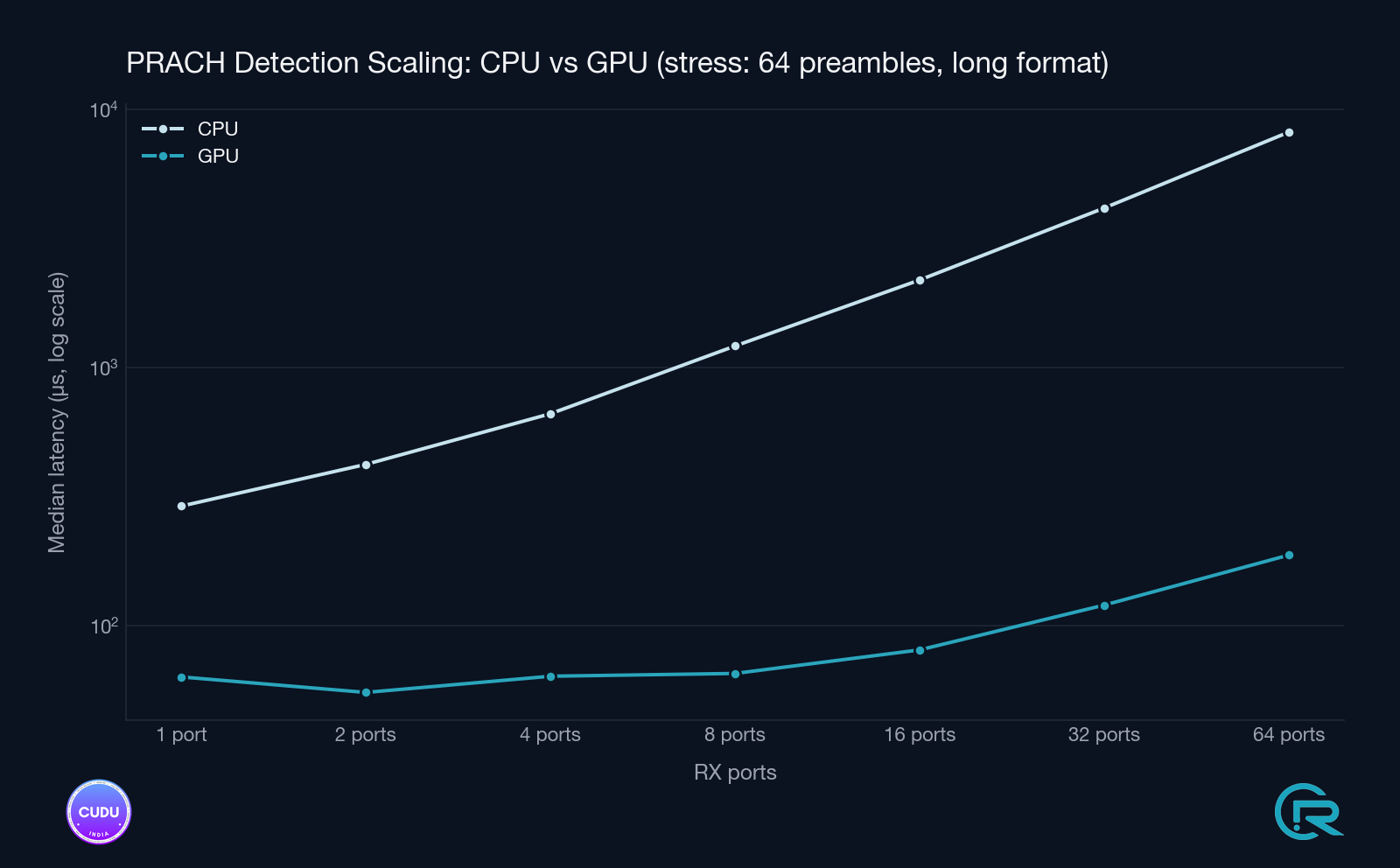
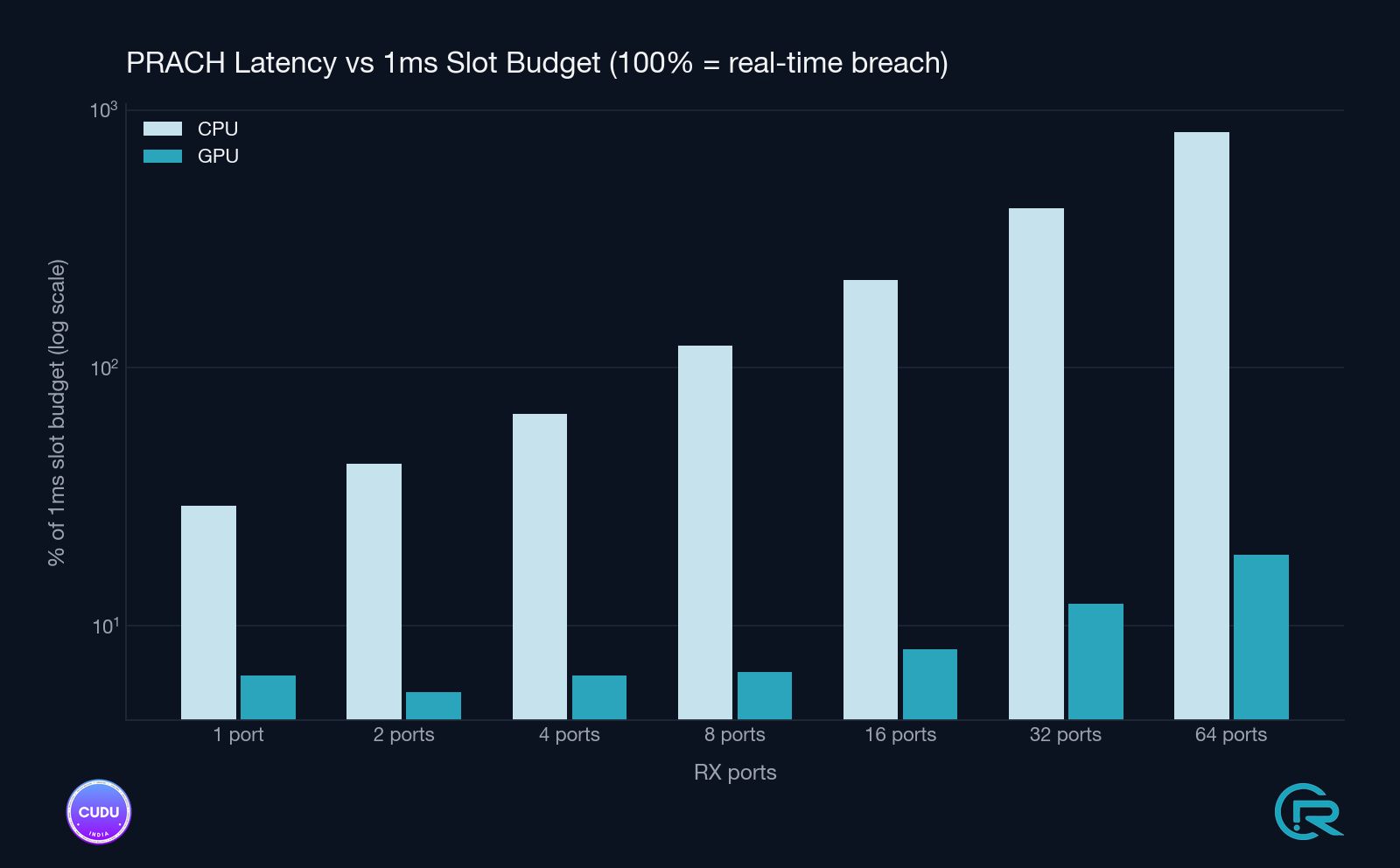
The budget-scaling chart is the one to keep in mind: even on the RTX A4000, a workstation-class card, the GPU detector stays well inside the PRACH timing budget across every tested configuration, with substantial headroom for higher antenna counts and denser preamble sets - precisely the configurations the CPU path cannot serve at all.
Measured Impact
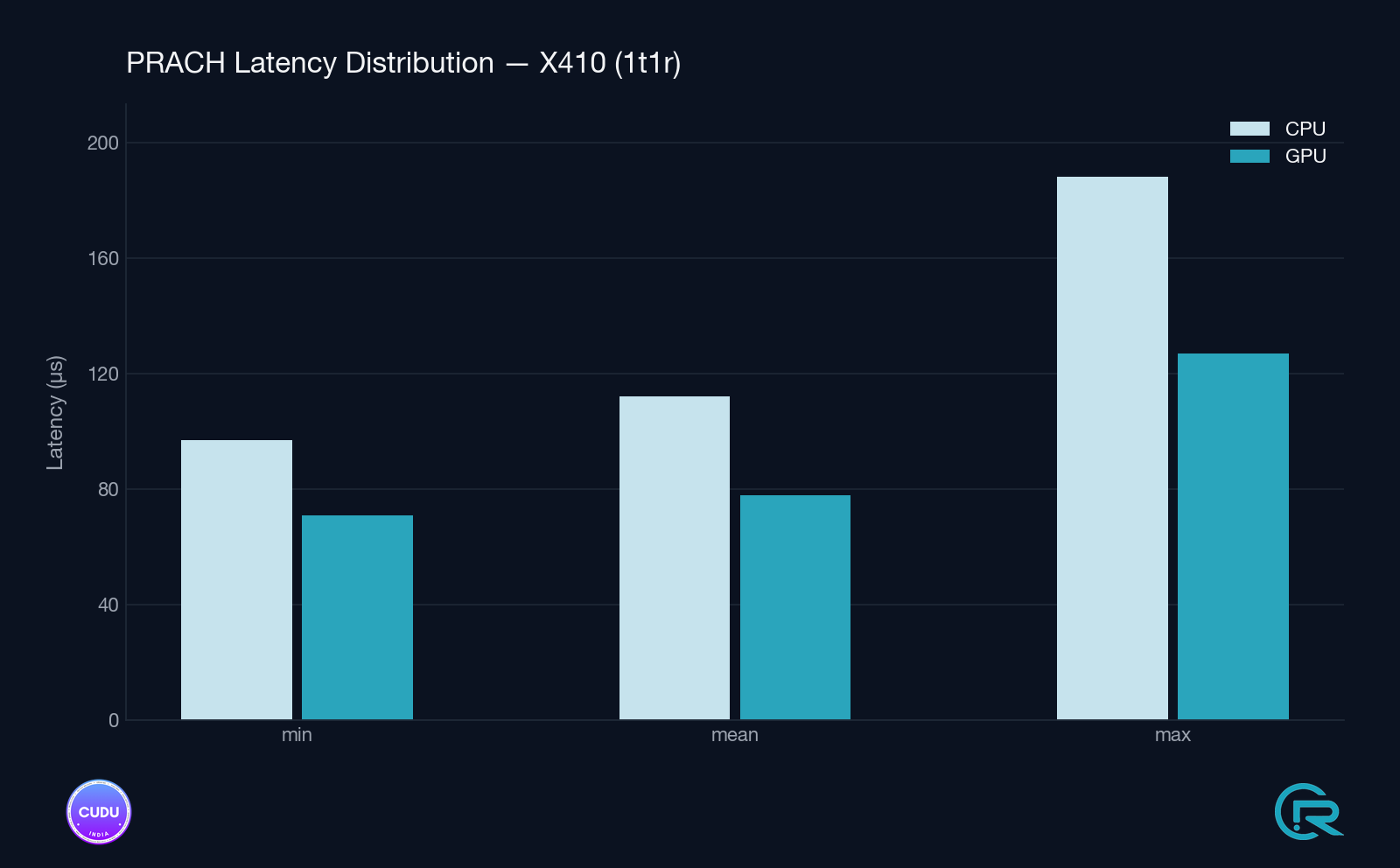
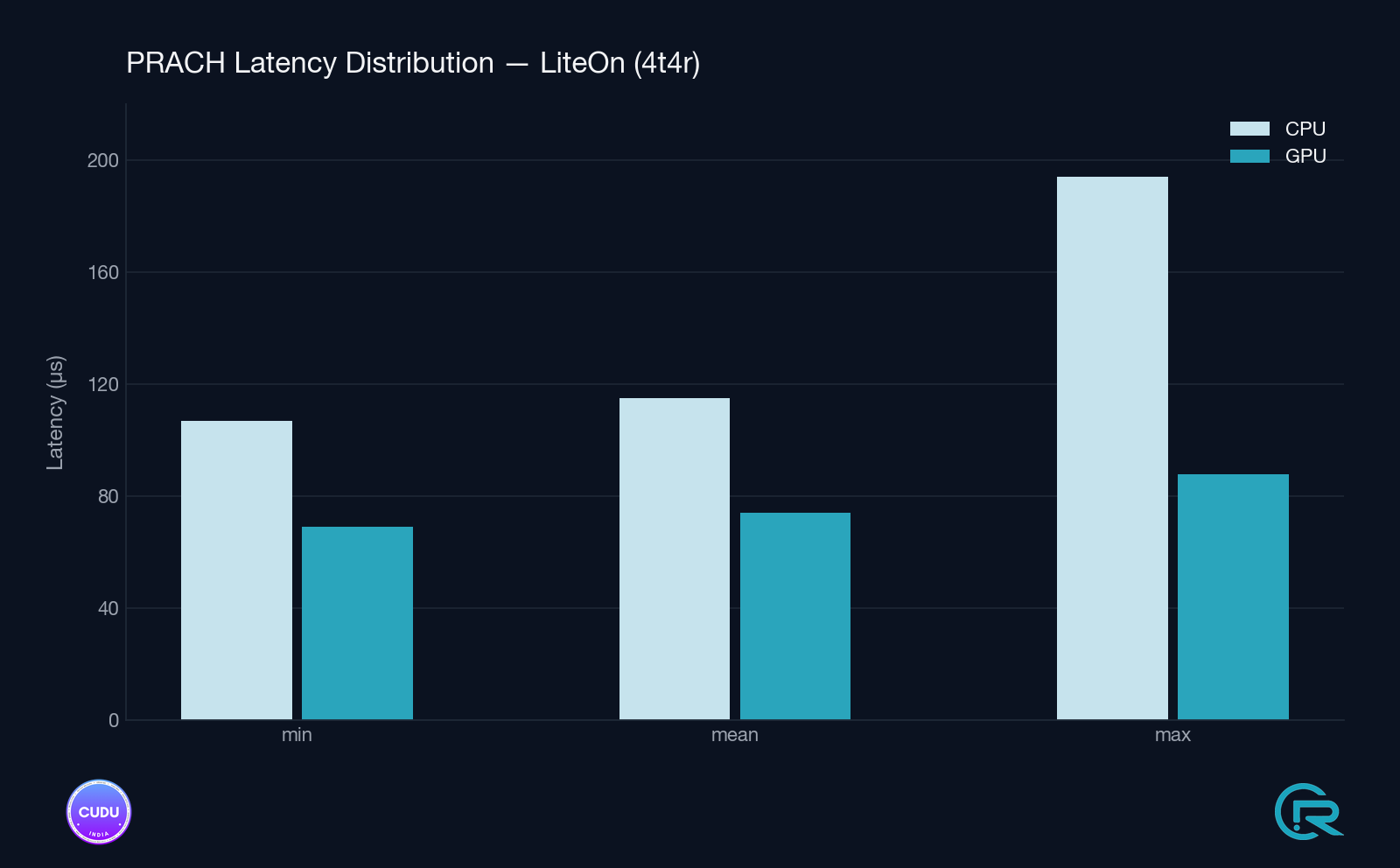
Validation was conducted on a live gNB with real over-the-air PRACH traffic, on an NVIDIA RTX A4000 - a workstation-class GPU, not a data-center accelerator. Tested across two RU setups: Ettus X410 (Split 8, 1T1R) and Liteon (Split 7.2, 4T4R). Stats are reported by the detector itself every 1000 detection windows, excluding the first window (which includes the one-time graph build).
Detection Latency - Steady State
| Setup | Path | Mean | Min | Max (tail) |
|---|---|---|---|---|
| Split 8 / Ettus X410 (1T1R) | GPU cuFFTDx | 78–79 µs | 70–72 µs | 103–127 µs |
| Split 8 / Ettus X410 (1T1R) | CPU FFTW | 111–113 µs | 97 µs | 154–188 µs |
| Split 7.2 / Liteon (4T4R) | GPU cuFFTDx | 74–75 µs | 69 µs | 82–88 µs |
| Split 7.2 / Liteon (4T4R) | CPU FFTW | 115 µs | 107 µs | 165–194 µs |
Improvement Summary
- Split 8 / X410 (1T1R): −30% mean (112 → 78 µs), −33% tail (161 → 107 µs)
- Split 7.2 / Liteon (4T4R): −36% mean (115 → 74 µs), −55% tail (187 → 87 µs)
The Liteon 4T4R setup shows the larger tail-latency improvement, consistent with the cuFFTDx fused kernel eliminating intermediate memory traffic that would otherwise create occasional outliers under memory-bandwidth pressure.

Why This Matters
This is a fundamentally different acceleration model from BBDEV. BBDEV is look-aside: descriptors enqueued, accelerator processes asynchronously, results dequeued. CUDA graphs are device-resident: the entire pipeline lives on the GPU between H2D and D2H. Both models belong in a serious vRAN stack and OCUDU now supports both, side by side, in the same binary.
Key advantages
- Decouples PHY logic from hardware specifics across two different accelerator ecosystems
- Enables plug-and-play accelerator integration via a uniform HAL
- Preserves software consistency and observability across paths
- Validated on workstation-class hardware; scales upward to A30 / A100 / H100 without redesign
Note: BBDEV is a DPDK abstraction supported by multiple FEC accelerator vendors; OCUDU’s BBDEV path is not Intel-specific. Intel ACC100 is the first instance demonstrated.
Availability
- Codebase: github.com/OCUDU-India/OCUDU (branch: hwacc_gpu)
- Documentation: docs.ocuduindia.org → PRACH GPU offload
Closing Thoughts
With LDPC offloaded via BBDEV to Intel ACC100 and PRACH detection now offloaded via CUDA graphs to NVIDIA GPUs, OCUDU’s accelerator-aware design is no longer a claim - it’s two production paths in the same binary, selected at startup, sharing the same observability, with transparent CPU fallback on both. Two acceleration paths, two vendors, one binary. The stack scales across hardware ecosystems because it was designed to.