
6 minute read
The OCUDU stack has historically run L2 and L1 inside a single monolithic process. While this model is simple from a deployment perspective, it tightly couples two very different parts of the gNB: the L2 stack, including MAC, RLC, PDCP, F1AP, RRC, and NGAP, and the L1/PHY layer, including Upper-PHY, channel processing, and RU-facing functions.
xFAPI enables OCUDU to move toward a fully operational FAPI L1/L2
split architecture, where odu_high and odu_low can run as
independent processes across the Small Cell Forum FAPI boundary.
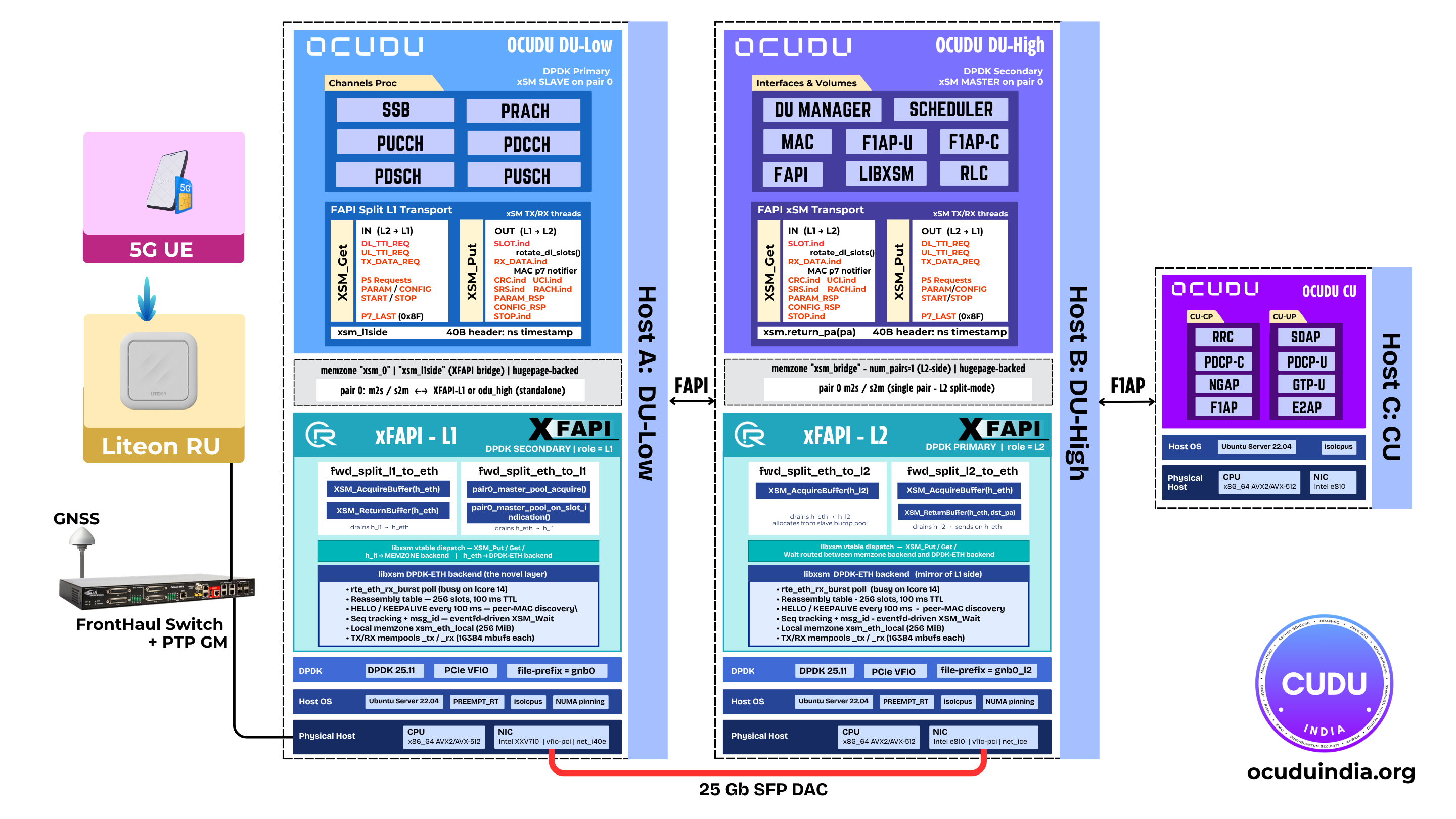
The main highlight here is xFAPI. xFAPI is the key interoperability layer that makes this split practical, open, and vendor-neutral. It allows L2 and L1 components to communicate through a clean FAPI-based boundary while reducing dependency on a single tightly coupled L1 implementation.
In simple terms, xFAPI turns the FAPI specification from a standard interface into a working interoperability layer.
Why xFAPI Matters for OCUDU
coRAN LABS has recently released an updated xFAPI version with support for the OCUDU split. This makes xFAPI a key enabler in bringing OCUDU’s FAPI L1/L2 split into a practical OpenRAN architecture.
xFAPI is important because it is not just a theoretical interoperability layer. It acts as a real bridge between OCUDU’s L2 and L1 components, allowing them to operate across a clean FAPI boundary.
FAPI defines the interface between L2 and L1. However, in real-world deployments, different vendors may implement FAPI with small variations in message formats, timing behavior, parameter handling, optional features, and transport mechanisms. These small differences can create major interoperability challenges.
This is exactly where xFAPI becomes valuable. It works as a vendor-neutral interoperability layer between L1 and L2, helping bridge implementation differences and supporting different IPC models.
For OCUDU, this means the same odu_high L2 stack can be positioned
to work with multiple L1 implementations, including OCUDU’s own
odu_low, Intel FlexRAN, OAI L1, and future GPU-accelerated L1
stacks such as NVIDIA Aerial.
In this context, xFAPI becomes the enabling layer that makes OCUDU’s FAPI L1/L2 split practical, portable, and vendor-neutral, while also creating a path toward future AI-RAN acceleration models.
OCUDU’s Split Architecture
The split architecture separates the stack into two independent binaries:
odu_highhandles the MAC scheduler, RLC, PDCP, F1AP, RRC, NGAP, and the MAC-side FAPI adaptor.odu_lowhandles Upper-PHY, channel processors, the PHY-side FAPI adaptor, and the RU front-end, supporting split 7.2 OFH or split 8.
The two processes exchange FAPI P5 control-plane and P7 data-plane messages over xSM, a DPDK-based shared-memory IPC transport.
xSM uses a hugepage-backed shared-memory region and lock-free SPSC rings, allowing both processes to exchange messages without kernel copies on the hot path.
xFAPI Makes the Boundary Truly Open
The value of the L1/L2 split is not only that the two layers are separated. The real value is that the boundary becomes explicit, portable, and vendor-neutral.
- Without xFAPI, the split may remain limited to one L1 implementation.
- With xFAPI, the boundary becomes reusable across vendors, platforms, and acceleration models.
This enables:
- Independent L1 and L2 lifecycle management.
- Vendor-neutral L1 integration.
- Support for different PHY implementations.
- A cleaner and more testable FAPI contract.
- A practical path toward GPU-accelerated AI-RAN.
This is what makes the OCUDU split meaningful from an OpenRAN perspective.
Execution Flow Across the xFAPI Boundary
A downlink TTI flows through the split architecture as follows:
- The MAC scheduler in
odu_highproducesdl_tti_request,ul_tti_request,ul_dci_request, andtx_data_requestfor slotN+K. - The L2 FAPI transport serializes each message into an xSM buffer with a 32-byte header containing message type, length, and timestamp.
- xSM enqueues the buffer into the L2-to-L1 ring and wakes the L1
receiver thread using an
eventfd. odu_lowreceives the buffer, deserializes it into the corresponding FAPI structure, and forwards it into the Upper-PHY.- After cell processing, L1 sends
slot_indication,rx_data_indication,crc_indication,uci_indication,srs_indication, andrach_indicationback to L2.
In total, seven FAPI interfaces cross the process boundary, covering 19 methods.
Implementation Highlights
The split path uses a lightweight xSM transport built around DPDK-friendly shared memory, fixed-size 64 KiB buffers, and per-direction lock-free SPSC rings.
A dedicated FAPI serialization layer marshals every P5 and P7 message into a compact, byte-aligned, length-prefixed wire format. Each message type has a hand-written serialize and deserialize pair, keeping the format reviewable and efficient.
A slot-aligned message bufferer ensures that L2-generated
messages for slot N+K are released to PHY at the correct slot
boundary. This gives L1 a clean and ordered burst per TTI instead of
arbitrary scheduling jitter.
The L1 receiver runs on a dedicated SCHED_FIFO thread and can be
pinned to an isolated CPU core. A stall detector logs
[XSM-RX-STALL] whenever wait, dispatch, or loop-gap intervals
exceed 10 ms, helping teams identify timing issues during platform
bring-up.
Observability Built In
The split architecture also adds strong observability features:
fapi_xsm_loggerprovides direction-tagged FAPI message logging.[XSM-RX-STALL]warnings expose scheduling delays on the L1 receiver thread.- Peer-liveness counters help operators detect when L1 disconnects.
All logs integrate with OCUDU’s standard ocudulog infrastructure,
allowing the split architecture to be debugged through the same
logging pipeline as the rest of the stack.
Measured Impact
The split was validated on a split 7.2 deployment with a live UE.
- The hot-path latency from
xSMput to L1 dispatch remained sub-microsecond on a hugepage-backed memzone. - No regressions were observed in DL/UL throughput, BLER, or HARQ behavior compared to the monolithic baseline at 100 MHz TDD.
Why This Matters for AI-RAN
This architecture is also an important step toward AI-RAN.
Once L1 is decoupled from L2 through a clean xFAPI boundary, the physical layer becomes a deployment choice rather than a codebase constraint.
That means OCUDU can be positioned to integrate GPU-accelerated, AI-ready PHY implementations such as NVIDIA Aerial behind the same FAPI boundary.
This is the key architectural shift. OCUDU is no longer limited to a tightly coupled L1/L2 model. With xFAPI, it can move toward a more open, flexible, and AI-ready RAN architecture.
Key Advantages
- xFAPI-enabled FAPI L1/L2 split.
- Vendor-neutral L1/L2 interoperability.
- Same
odu_highL2 stack across multiple L1 implementations. - Zero-kernel-copy xSM transport on the hot path.
- FAPI serialization.
- Slot-aligned buffering for deterministic PHY timing.
- Independent lifecycle management of L1 and L2.
- Clear path toward GPU-accelerated AI-RAN.
Useful Links
- Architecture deep-dive: OCUDU RAN Disaggregated FAPI Split
- YouTube overview: xFAPI Enables OCUDU’s FAPI L1/L2 Split
- Demo video: OCUDU + xFAPI Demo - Disaggregated FAPI interface in OCUDU RAN
- OCUDU India docs: docs.ocuduindia.org
- coRAN LABS xFAPI repository: github.com/coranlabs/xFAPI
Closing Thought
The real achievement is not simply that OCUDU can separate L1 and L2. The real achievement is that xFAPI makes the split open, portable, and vendor-neutral.
By bringing a practical FAPI boundary into the OCUDU architecture, xFAPI enables OCUDU to move beyond a monolithic gNB model and toward an OpenRAN architecture where L1 can be selected, replaced, accelerated, and optimized independently.
xFAPI is the bridge that makes OCUDU’s FAPI split possible, and it is the foundation for OCUDU’s journey toward open, vendor-neutral AI-RAN.