PRACH Detection offload to GPU
14 minute read
Highlights
- Full detection pipeline on GPU - correlation, IDFT, power accumulation, and peak detection all run device-resident; only the cbf16 PRACH buffer crosses H2D and only the argmax result (~1 KB) crosses D2H per detection window.
- cuFFTDx fused kernel - for the standard PRACH IDFT sizes (256-point for short format, 1024-point for long format), a single cuFFTDx device kernel fuses conjugate-product correlation, bin reorder, IDFT, and power normalisation into one launch with no intermediate device-memory traffic.
- CUDA-graph execution - the full pipeline is captured into a
cudaGraphExec_tkeyed by detection configuration. Hot-path cost is onecudaGraphLaunch + cudaStreamSynchronizeper slot window. - Zero-allocation hot path - all device and pinned-host buffers are
pre-allocated at construction for worst-case dimensions (64 ports × 12
symbols);
detect()touches no allocator. - Configuration-driven - select via the
OCUDU_PRACH_DFT_BACKEND=gpu_fullenvironment variable at gNB startup; no code changes, no YAML required. - Transparent fallback - if no CUDA device is present or the build flag is absent, the runtime falls back to the CPU-FFTW detector silently.
- Measured ~30–36 % mean latency reduction - short-format detect drops from ~112–115 µs (CPU FFTW) to ~74–79 µs (GPU cuFFTDx), with up to 55 % tail compression, measured on live gNB with X410 (Split 8) and Liteon (Split 7.2) (see Section 7).
1. Prerequisites
1.1 Hardware
- NVIDIA GPU: Ampere or later (SM86+) for the fused cuFFTDx fast path. Tested on RTX A4000 (SM86, runs the cuFFTDx fused kernel) and RTX 8000 (SM75, falls back to the cuFFT three-kernel path automatically slightly higher overhead). Volta (SM70) and other Turing cards behave like RTX 8000.
- x86-64 CPU with at least AVX2 (the CPU-FFTW fallback detector uses AVX-512 when available).
- GPU should be on the same NUMA node as the upper-PHY worker cores to minimise PCIe latency.
- At least 512 MB of free GPU device memory (worst-case allocation is approximately 300 MB for 64 ports × 12 symbols × 4096-bin DFT).
1.2 Software
| Component | Minimum version | Notes |
|---|---|---|
| CUDA Toolkit | 12.0 | nvcc, cuda_runtime.h, cufft.h required. |
| NVIDIA MathDx | 26.03 | Provides cufftdx.hpp; installed at /opt/nvidia-mathdx-26.03.0-cuda13/. |
| NVIDIA driver | 525+ | Must match or exceed the CUDA Toolkit version. |
| Linux kernel | 5.15+ | Standard Ubuntu 22.04 LTS kernel is sufficient. |
| CMake | 3.18+ | Required for CUDA_SEPARABLE_COMPILATION. |
| DU build flags | ENABLE_DFT_GPU=ON | See Section 5. |
1.3 Driver and CUDA installation
# Confirm NVIDIA driver is loaded and GPU is visible:
nvidia-smi
# Expected output includes device name, driver version ≥ 525, CUDA version ≥ 12.0:
# +-----------------------------------------------------------------------------+
# | NVIDIA-SMI 535.x Driver Version: 535.x CUDA Version: 12.2 |
# +-----------------------------------+-------------------+---------------------+
# | GPU 0 RTX A4000 Off | | |
# Verify CUDA Toolkit is installed:
nvcc --version
# Expected: Cuda compilation tools, release 12.x
# Verify cuFFT library is present:
ls /usr/local/cuda/lib64/libcufft*
# Install CUDA Toolkit if missing (Ubuntu 22.04):
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get install -y cuda-toolkit-12-2
1.4 NVIDIA MathDx (cuFFTDx) installation
cuFFTDx is a header-only device library distributed as part of NVIDIA MathDx.
The build system looks for it under /opt/nvidia-mathdx-26.03.0-cuda13/.
# Download MathDx 26.03 from NVIDIA Developer:
# https://developer.nvidia.com/mathdx-downloads
# (login required; select "MathDx 26.03 for CUDA 13" tarball)
# Extract to the expected path:
sudo tar -xf nvidia-mathdx-26.03.0-cuda13.tar.gz -C /opt/
sudo ln -s /opt/nvidia-mathdx-26.03.0-cuda13 /opt/nvidia-mathdx
# Verify the CMake config file is reachable:
ls /opt/nvidia-mathdx-26.03.0-cuda13/nvidia/mathdx/26.03/lib/cmake/
# Expected: mathdxConfig.cmake cufftdxConfig.cmake ...
# Quick sanity-check: confirm cufftdx.hpp is present:
find /opt/nvidia-mathdx-26.03.0-cuda13 -name "cufftdx.hpp" | head -3
1.5 GPU persistence and clock settings (recommended for production)
# Enable GPU persistence mode to avoid cold initialisation on first CUDA call:
sudo nvidia-smi -pm 1
# Lock SM and memory clocks for deterministic latency (RTX A4000 example):
sudo nvidia-smi -lgc 1440 # lock GPU clocks (MHz); check your card's max
sudo nvidia-smi -lmc 1215 # lock memory clocks
# Confirm:
nvidia-smi -q -d CLOCK | grep -A4 "Clocks"
# Disable GPU power throttling:
sudo nvidia-smi --auto-boost-default=0
Setting persistence mode and locking clocks eliminates GPU frequency-scaling jitter, which can otherwise cause occasional tail-latency outliers during low-traffic periods when the GPU would otherwise downclock.
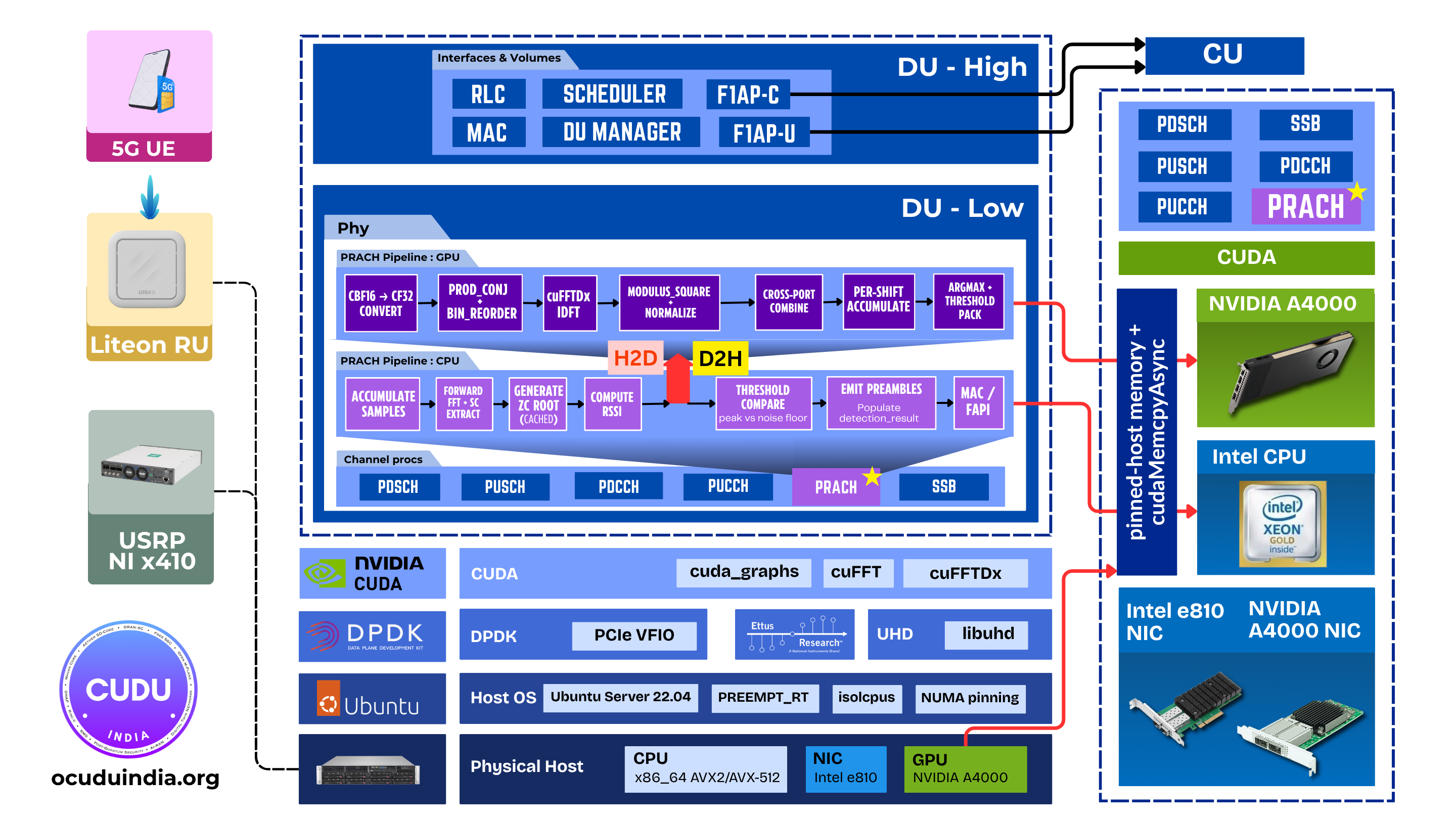
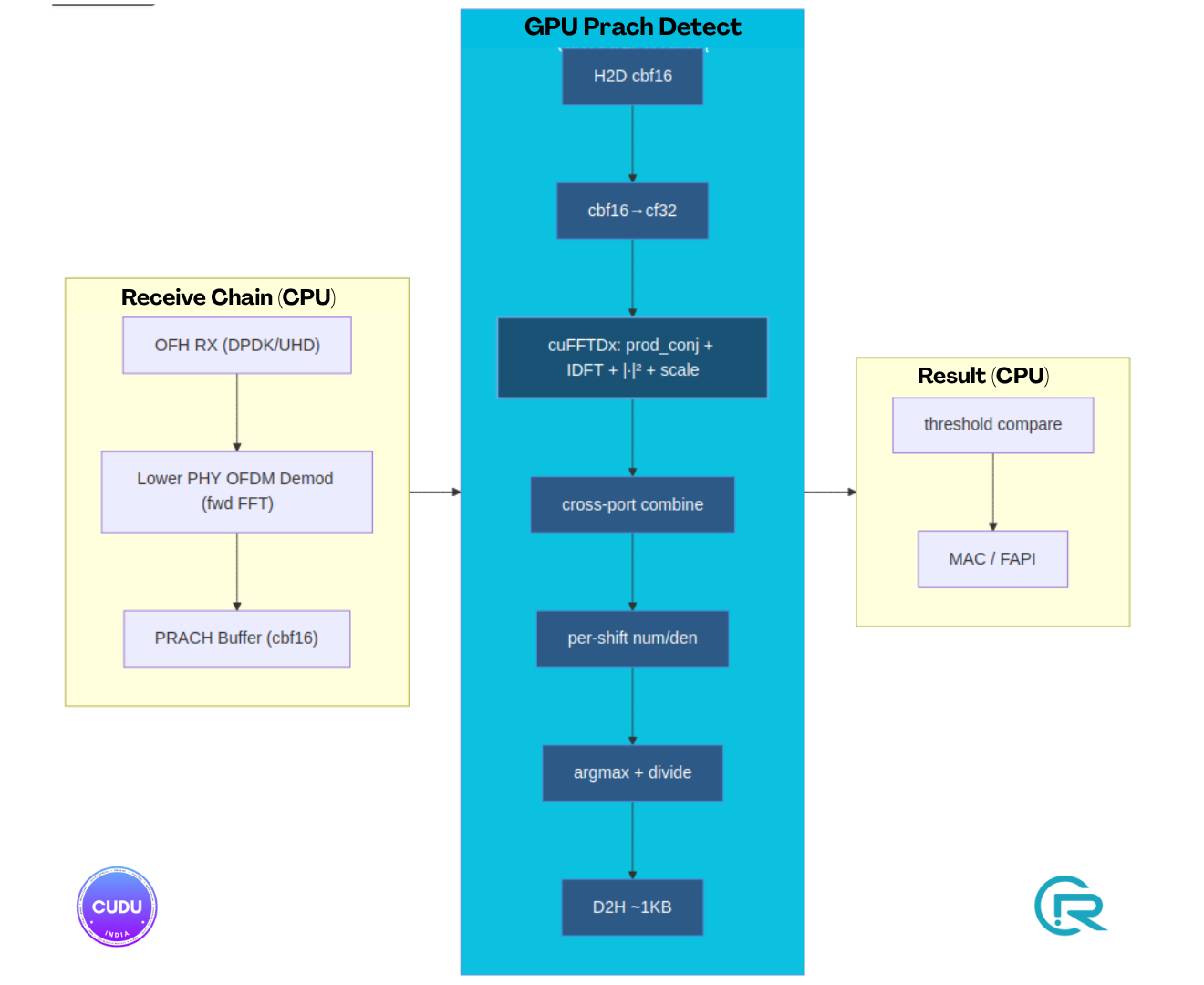
2. Architecture overview
2.1 Where PRACH detection sits in the uplink chain
PRACH detection is the 5G Random Access Channel procedure: the gNB must detect
which of up to 64 preamble sequences was transmitted by a UE, and compute the
timing advance from the peak position. On the CPU path this is performed by
prach_detector_generic_impl using FFTW IDFTs. On the GPU path,
prach_detector_gpu_impl replaces the inner detection loop entirely.
The detection step runs after the lower-PHY OFDM demodulator (forward FFT) and before the MAC PRACH result callback. Everything upstream (OFH RX, lower-PHY sample windowing, OFDM forward FFT) and downstream (MAC/DU-High random-access response) stays on CPU.
3. Implementation summary
The integration is a hardware-abstraction layer that plugs into the existing
upper-PHY factory pattern via the prach_detector interface. Four things are
worth knowing:
Fused device kernel. For standard PRACH IDFT sizes (256 for short format, 1024 for long format), a single cuFFTDx block-FFT kernel (
k_fused_prach_idft) performs conjugate-product correlation, DFT-bin reorder, IDFT, and power normalisation in one GPU thread block per batch element. No intermediate complex buffer crosses shared memory; onlyfloatpower values are written out. For DFT sizes outside the supported set {128, 256, 512, 1024, 2048, 4096}, the path falls back to three separate kernels pluscufftExecC2C.CUDA graph caching. The pipeline is captured into a
cudaGraphExec_ton the firstdetect()call for each unique configuration shape. The cache key has 9 fields: format (long vs short), number of ZC sequences, ports × symbols, DFT size, sequence length L_ra, cyclic-shift count, window width, window margin, and combine iteration count. Subsequent calls with the same key cost onecudaGraphLaunch + cudaStreamSynchronize; the graph dispatcher and all argument pointers are baked into the graph at capture time.Zero-allocation hot path. All device buffers (
d_preamble,d_combined,d_idft,d_mod_sq,d_num,d_den,d_argmax_*) and pinned host staging buffers (h_preamble,h_root,h_argmax_*) are allocated once at construction for worst-case dimensions (64 ports × 12 symbols × 4096 DFT bins).detect()calls no allocator on the hot path.Root sequence caching. Zadoff-Chu root sequences are generated on CPU by
prach_generator_impland cached inh_root(pinned host). The cache is invalidated only when format, root sequence index, restricted set, ZCZ, or derived dimensions change. On a stable single-cell gNB config this never re-evaluates after the first detection window.
A 9-field graph cache key captures all dimensions that affect kernel grid shapes. This means:
- A cell running format 0 with ZCZ 0 builds one graph (long=true, seq=64, shifts=1, win_width=CP_bins, …).
- A cell running format 0 with ZCZ 14 builds a different graph (seq=1, shifts=64, different win_width). Each key pays a one-time build cost (3–6 ms) and is cached for the lifetime of the detector instance.
4. GPU pipeline - kernel chain
The pipeline captured in the CUDA graph runs the following stages in stream order:
H2D h_root_all → d_root_all (ZC roots, cf32, ~430 KB)
H2D h_window_starts → d_window_starts (uint32, ~256 B)
[per combine_iter]
H2D h_preamble[it] → d_preamble (cbf16, ~13 KB / slice)
k_cbf16_to_cf_init_or_add (cbf16 → cf32, init on it=0 or += on it>0)
→ d_combined
[cuFFTDx primary path, sizes ∈ {128, 256, 512, 1024, 2048, 4096}, SM86]
k_fused_prach_idft<N> (prod_conj + bin_reorder + cuFFTDx IDFT
+ |·|² + 1/(dft_size·L_ra) scale) → d_mod_sq
[cuFFT fallback, DFT sizes outside the supported set above]
k_prod_conj_bin_reorder → d_idft
cufftExecC2C (CUFFT_INVERSE) → d_idft
k_modulus_square_normalize → d_mod_sq
k_combine_mod_sq (non-coherent cross-port + symbol sum)
→ d_mod_sq_combined
k_per_shift_accumulate_combined (per cyclic-shift, per bin in window:
num[i] = signal_sample × window_scale;
den[i] = reference_window_energy − num[i])
→ d_num, d_den
k_finalize_per_shift_xseq (num[i]/|den[i]| argmax per shift)
→ d_argmax_idx, d_argmax_val, d_num_at_argmax
D2H d_argmax_idx/val/num → h_argmax_idx/val/num (~1 KB)
After cudaStreamSynchronize, the CPU iterates over at most 64
(seq × shift) elements, applies the detection threshold, and emits
prach_detection_result::preamble_indication structs.
PCIe transfer budget
| Transfer | Size (format 0, 4 ports) | Duration at PCIe Gen4 ×16 |
|---|---|---|
| H2D PRACH buffer (cbf16) | ~13 KB | < 1 µs |
| H2D ZC roots (cf32, cold) | ~430 KB | ~20 µs (cached after first window) |
| H2D window starts | 256 B | negligible |
| D2H argmax results | ~1 KB | < 1 µs |
| Total hot-path | ~14 KB | < 1 µs |
ZC root H2D cost is paid only on a root cache miss (config change or first window); in steady-state operation it does not appear on every detect.
5. Configuration
No YAML changes are required. The GPU detector is selected at runtime via an environment variable.
5.1 Enable GPU PRACH detection
export OCUDU_PRACH_DFT_BACKEND=gpu_full
Set this before starting the gNB process. On gNB startup, if a CUDA device is found, you will see on stdout:
PRACH DFT backend: gpu_full (CUDA-shell detector)
If no CUDA device is present or the build was compiled without
ENABLE_DFT_GPU=ON, the message will be:
OCUDU_PRACH_DFT_BACKEND=gpu_full but GPU detector unavailable, falling back
and the CPU-FFTW detector will be used automatically - no crash, no manual intervention required.
5.2 Verification at startup
Shortly after the first PRACH window arrives, stderr will contain:
[prach_detector_gpu] constructed: idft_long=1024 idft_short=256 max_batch=768 device_buffers_mib=N
(above CPU instance is a gpu_full inner-fallback, idle in normal operation)
[prach_detector_gpu] graph cache miss #1: long=false seq=64 ports*sym=1 dft=256 shifts=1 win_width=116 build=4953us (cached_graphs=1)
The build=...us line is the one-time CUDA graph construction cost. Subsequent
detection windows for the same configuration will not print this line.
5.3 Unset / CPU path (default)
Do not set OCUDU_PRACH_DFT_BACKEND (or unset it) to run the CPU-FFTW detector:
unset OCUDU_PRACH_DFT_BACKEND
No rebuild is required to switch between GPU and CPU paths.
6. Build guide
6.1 gNB with 7.2 fronthaul + DPDK + GPU PRACH acceleration
cd ~/kriish/ocudu_gpu_prach
mkdir -p build_gpu_split7_2
cd build_gpu_split7_2
cmake -DDU_SPLIT_TYPE=SPLIT_7_2 \
-DENABLE_DFT_GPU=ON \
-DENABLE_DPDK=True \
-DASSERT_LEVEL=MINIMAL \
../
make -j$(nproc)
Binary: build_gpu_split7_2/apps/gnb/gnb.
Note:
ENABLE_DFT_GPU=ONrequires NVIDIA MathDx 26.03 with cuFFTDx to be installed at/opt/nvidia-mathdx-26.03.0-cuda13/before CMake configure time. The configure step will error withENABLE_DFT_GPU=ON requires NVIDIA MathDx with cuFFTDx.if the package is not found. See Section 1.4.
6.2 gNB with 7.2 fronthaul + DPDK + GPU PRACH + HW LDPC (ACC100)
cmake -DDU_SPLIT_TYPE=SPLIT_7_2 \
-DENABLE_DFT_GPU=ON \
-DENABLE_DPDK=True \
-DENABLE_PDSCH_HWACC=True \
-DENABLE_PUSCH_HWACC=True \
-DASSERT_LEVEL=MINIMAL \
../
make -j$(nproc)
6.3 What the build produces
ENABLE_DFT_GPU=ON builds the ocudu_hal_dft_gpu static library from two
CUDA translation units:
| Source | Contents |
|---|---|
lib/hal/cuda/prach_detector_gpu_kernel.cu | k_cbf16_to_cf, k_prod_conj_bin_reorder, k_modulus_square_normalize, k_combine_mod_sq, k_per_shift_accumulate_combined, k_finalize_per_shift_xseq, k_zero_floats |
lib/hal/cuda/prach_detector_gpudx_kernel.cu | k_fused_prach_idft<N> (cuFFTDx, sizes 128/256/512/1024/2048/4096, SM86) |
The library links against CUDA::cudart, CUDA::cufft, and
mathdx::cufftdx. The main gNB binary links this library only when
ENABLE_DFT_GPU=ON.
6.4 PRACH detector benchmark
cd build_gpu_split7_2
make -j$(nproc) prach_detector_benchmark
# Run CPU baseline (FFTW):
./tests/benchmarks/phy/upper/channel_processors/prach_detector_benchmark
# Run GPU path (set env var, then benchmark):
OCUDU_PRACH_DFT_BACKEND=gpu_full \
./tests/benchmarks/phy/upper/channel_processors/prach_detector_benchmark
The benchmark sweeps nof_rx_ports ∈ {1, 2, 4}, format {zero, B4},
zcz ∈ {0, 1, 14}, and nof_preambles ∈ {4, 64}.
7. Results
All measurements are from live gNB runs with real over-the-air PRACH traffic.
Stats are reported by the detector itself every 1000 detection windows; the
max in the first window includes the one-time CUDA graph build cost.
Note on hardware: the numbers below are from the RTX A4000 (SM86), which runs the cuFFTDx fused kernel. On the RTX 8000 (SM75) the code falls back to the cuFFT three-kernel path; latency on that card is higher than what’s shown here (an exact number is not yet published - expect roughly 1.3–1.6× the A4000 figures, dominated by the extra kernel-launch and intermediate-buffer overhead).
7.1 Test environments
Setup A - Split 8 / X410 RU (1T1R)
| Item | Value |
|---|---|
| Host | x86_64, AVX-512 |
| GPU | NVIDIA RTX A4000 (SM86, 16 GB GDDR6) |
| OS | Ubuntu 22.04 LTS, kernel 5.15 |
| CUDA Toolkit | 12.2 / NVIDIA MathDx 26.03 |
| RU | Ettus X410, Split 8, 1T1R |
| PRACH config | Short format (B4), seq=64, ports×sym=1, DFT=256, shifts=1 |
Setup B - Split 7.2 / Liteon RU (4T4R)
| Item | Value |
|---|---|
| Host | Same host as Setup A |
| GPU | NVIDIA RTX A4000 (SM86, 16 GB GDDR6) |
| RU | Liteon 7.2-split, 4T4R, band n78 |
| PRACH config | Short format (B4), seq=64, ports×sym=1, DFT=256, shifts=1 |
7.2 Detection latency - steady-state (windows 2000–10000)
Mean / min / max over rolling 1000-window intervals, excluding the first window (which includes the one-time graph build cost).
| Setup | Path | mean | min | max |
|---|---|---|---|---|
| Split 8, X410 1T1R | GPU cuFFTDx | 78–79 µs | 70–72 µs | 103–127 µs |
| Split 8, X410 1T1R | CPU FFTW | 111–113 µs | 97 µs | 154–188 µs |
| Split 7.2, Liteon 4T4R | GPU cuFFTDx | 74–75 µs | 69 µs | 82–88 µs |
| Split 7.2, Liteon 4T4R | CPU FFTW | 115 µs | 107 µs | 165–194 µs |
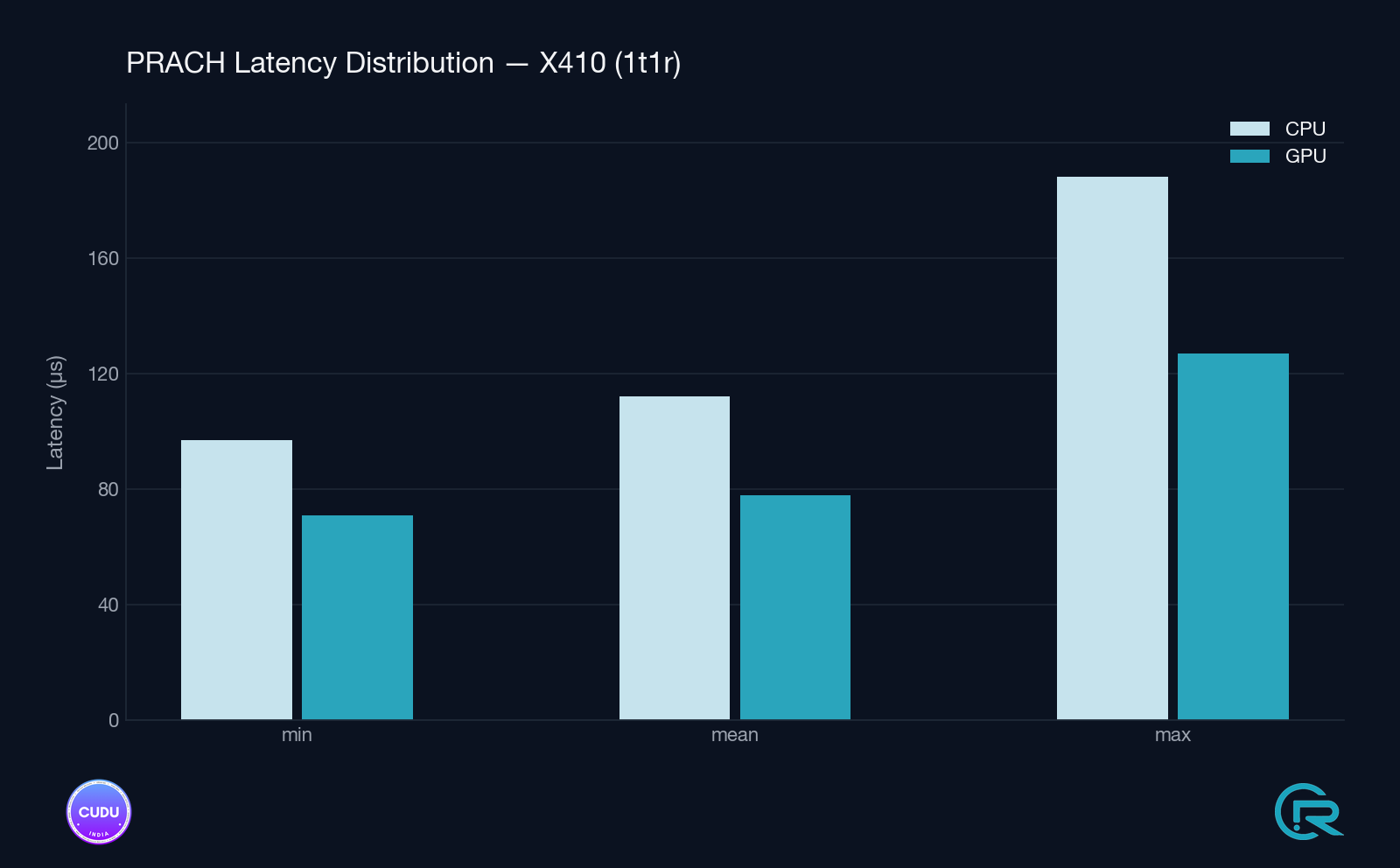
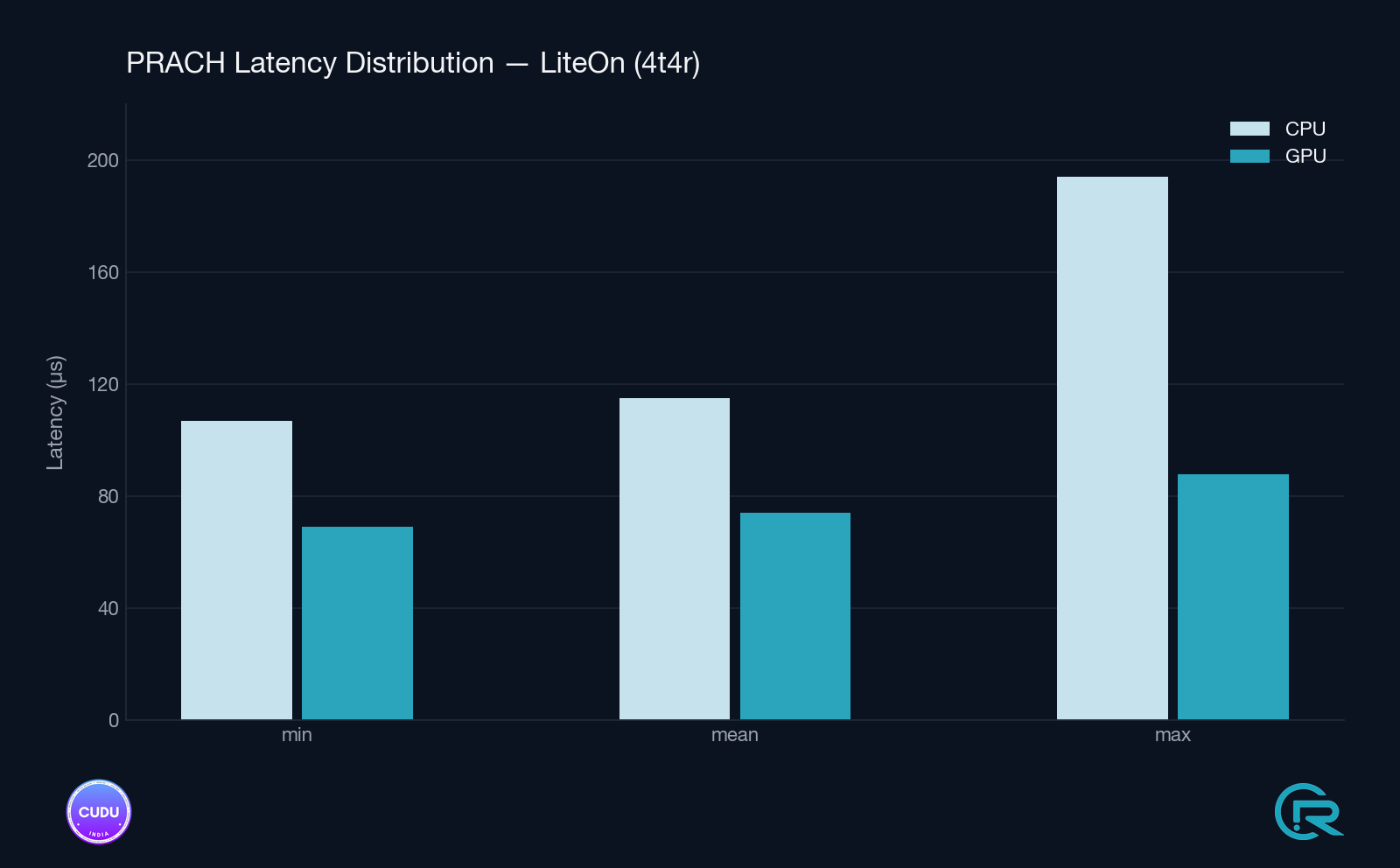

7.3 Improvement summary
| Setup | Mean Δ | Max (tail) Δ |
|---|---|---|
| Split 8, X410 1T1R | −30 % (112 → 78 µs) | −33 % (161 → 107 µs) |
| Split 7.2, Liteon 4T4R | −36 % (115 → 74 µs) | −55 % (187 → 87 µs) |
The Liteon 4T4R setup shows a larger tail-latency improvement, consistent with the cuFFTDx fused kernel eliminating intermediate memory traffic that would otherwise create occasional outliers under memory-bandwidth pressure.
7.4 GPU-path scaling and timing-budget headroom
Beyond the CPU vs GPU comparison, the GPU detector was characterised on its own across configurations and under stress to understand how it behaves with increasing antenna count and how much headroom it leaves against the PRACH timing budget.
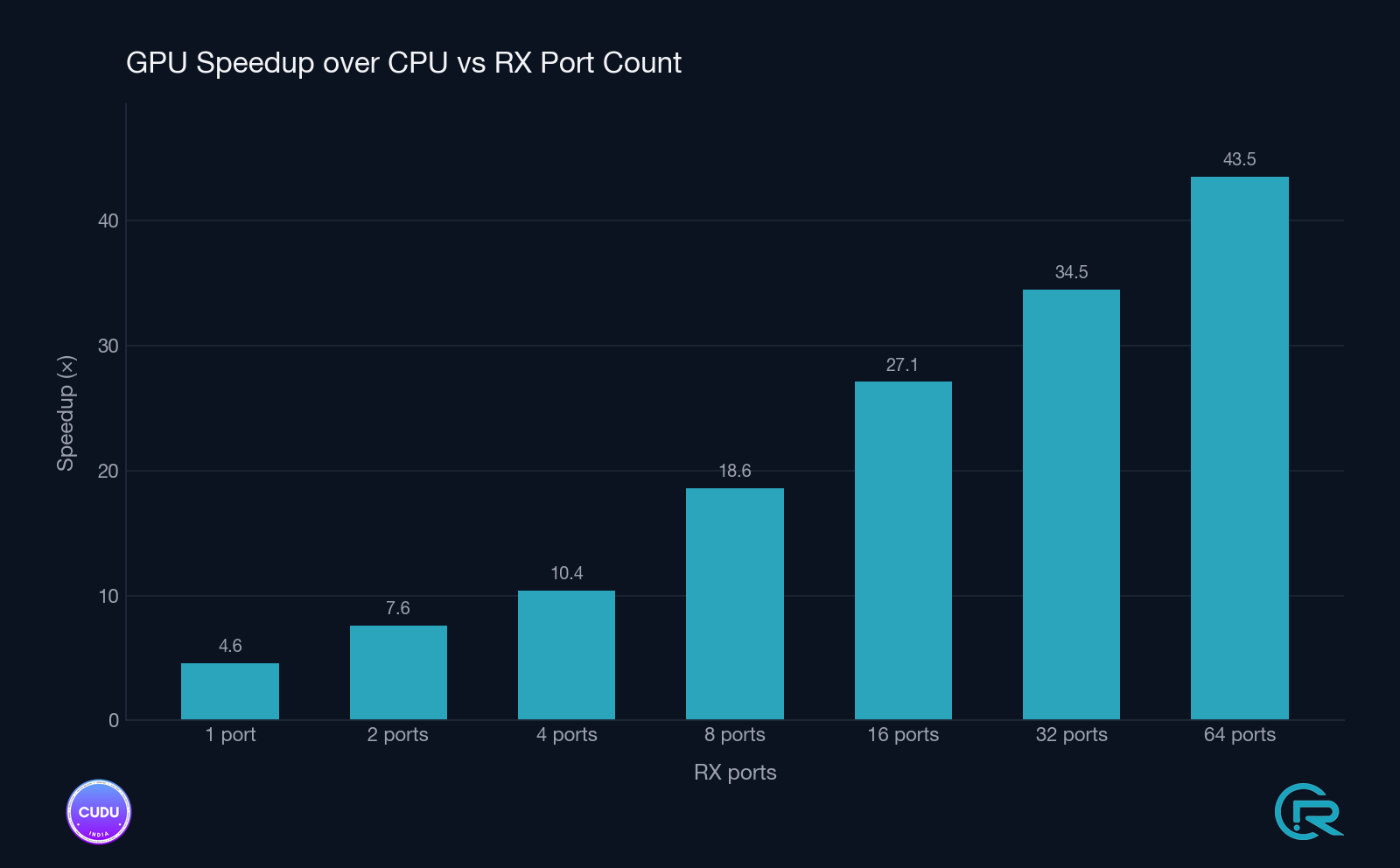
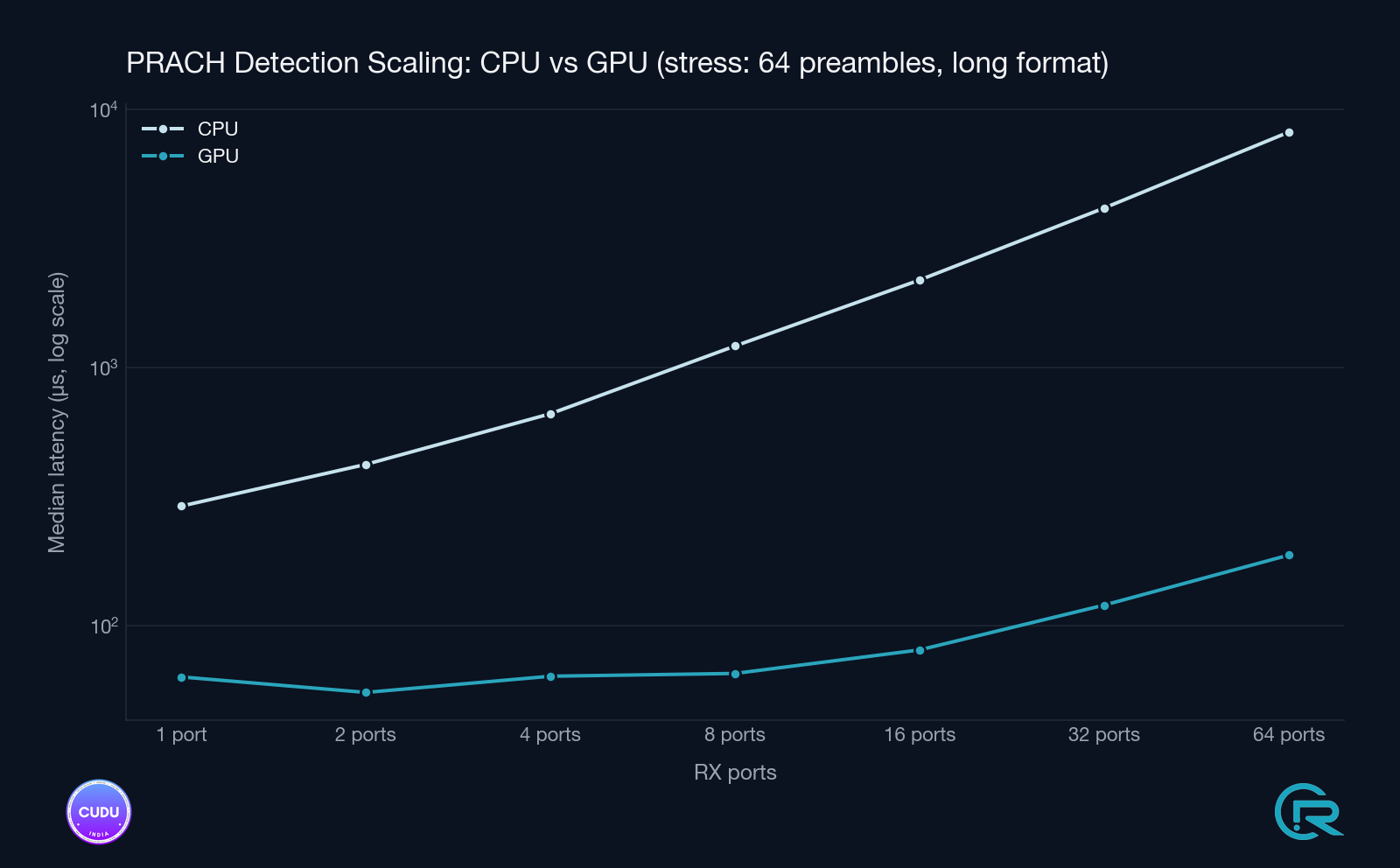
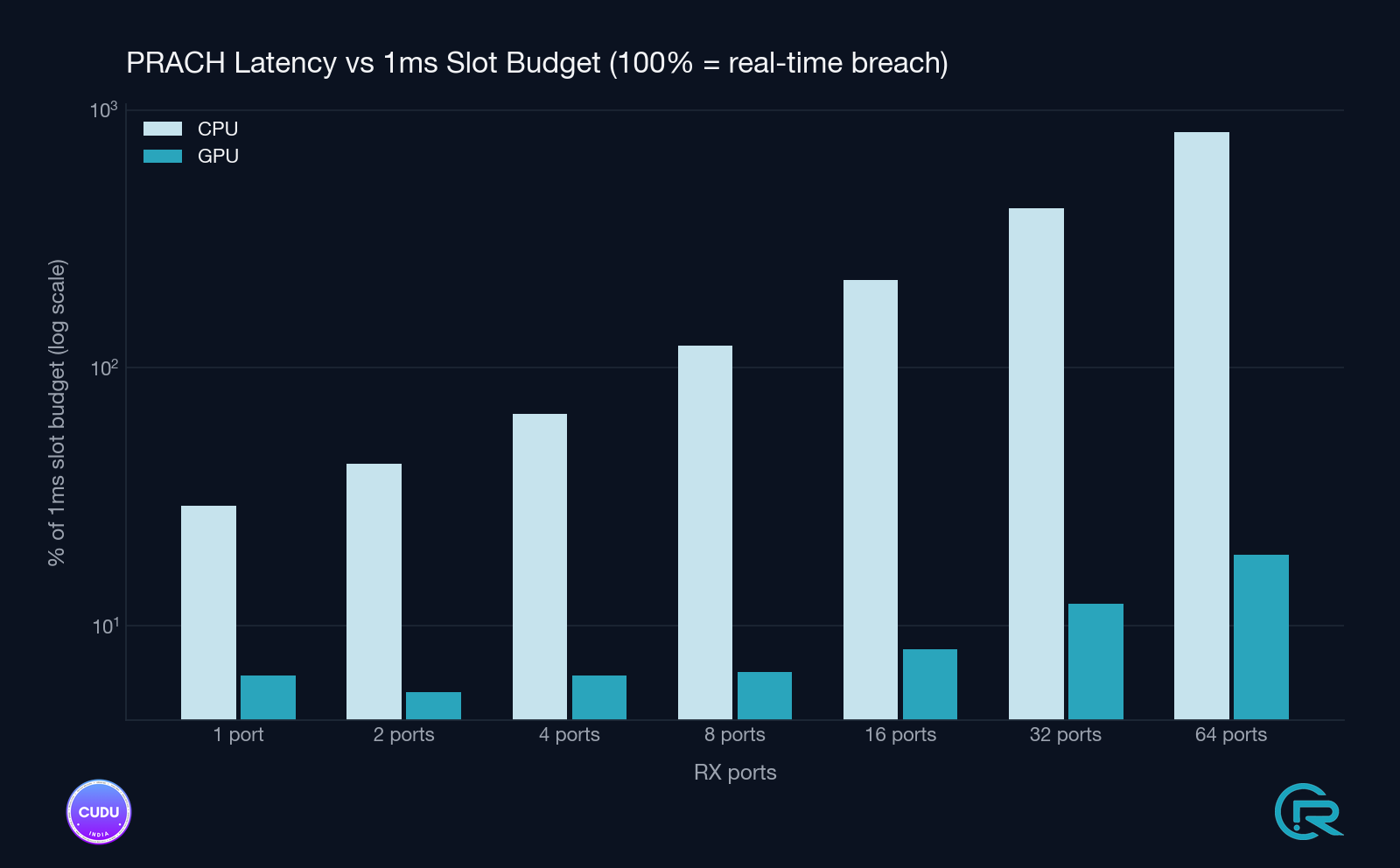
7.5 Cold-start graph build cost
The first detection window pays a one-time CUDA graph construction penalty. This occurs at gNB startup, before any UE can complete the random-access procedure (UEs do not transmit PRACH until SIB1 is received), so it does not affect UE experience.
| Setup | Graph build time |
|---|---|
| Split 8, X410 1T1R (short format, DFT=256) | 4 953 µs |
| Split 7.2, Liteon 4T4R (short format, DFT=256) | 3 547 µs |
After the first window for each configuration key the cost does not recur.
graph_builds=1 and cached_graphs=1 remain constant throughout the run,
confirming a single graph serves the entire session.
8. Metrics and observability
The GPU detector emits structured log lines to stderr independently of the
YAML metrics system. No YAML change is needed to observe these.
8.1 GPU detector stats (every 1000 detects)
[prach_detector_gpu] graph cache miss #1: long=false seq=64 ports*sym=1 dft=256 shifts=1 win_width=116 build=4953us (cached_graphs=1)
[prach_detector_gpu] stats: detects=1000 graph_builds=1 cached_graphs=1 mean=86us min=72us max=6698us (last_window=1000)
[prach_detector_gpu] stats: detects=2000 graph_builds=1 cached_graphs=1 mean=79us min=72us max=109us (last_window=1000)
graph_builds- total CUDA graph cache misses since construction. In normal operation this reaches 1 (or 2 for cells with both long and short format PRACH) and stays there.cached_graphs- number of graphs currently in the cache.maxin the first 1000-detect window includes the one-time graph build; subsequent windows will showmax ≈ 100–150 µs.
8.2 CPU fallback detector stats (every 1000 detects)
When OCUDU_PRACH_DFT_BACKEND=gpu_full is active, the inner CPU fallback
detector (prach_detector_generic_impl) is present but never invoked during
normal operation. Its stats line will show detects=0:
[prach_detector_cpu] stats: detects=0 mean=0us min=0us max=0us (last_window=1000)
detects=0 throughout the gNB run confirms the GPU path is handling all
windows. Any non-zero value indicates a config path that routed to the CPU
fallback - worth investigating if observed.
8.3 Upper-PHY YAML metrics (optional, for A/B comparison)
The logging_prach_detector_decorator wraps the detector and reports
per-detect timing and results to the configured logger. Enable in the YAML:
metrics:
enable_log: true
layers:
enable_du_low: true
periodicity:
du_report_period: 1000
This produces the standard per-PRACH-window timing line regardless of whether the GPU or CPU detector is active, enabling direct side-by-side comparison from the same log format.
9. Deployment checklist
- Install NVIDIA driver ≥ 525 and CUDA Toolkit ≥ 12.0 on the host (Section 1.3).
- Install NVIDIA MathDx 26.03 at
/opt/nvidia-mathdx-26.03.0-cuda13/(Section 1.4). - Enable GPU persistence mode and (optionally) lock clocks (Section 1.5).
- Build the gNB with
ENABLE_DFT_GPU=ON(Section 6.1). - Set
OCUDU_PRACH_DFT_BACKEND=gpu_fullin the gNB process environment (Section 5.1). - Start the gNB and confirm
PRACH DFT backend: gpu_full (CUDA-shell detector)on stdout. - Wait for the first PRACH window and confirm
graph cache miss #1 ... build=Xuson stderr. - After 1000 detection windows, confirm
[prach_detector_gpu] stats: ... graph_builds=1and[prach_detector_cpu] stats: detects=0. - Optionally enable
metrics.layers.enable_du_lowfor per-window latency logging (Section 8.3).
10. References
- NVIDIA cuFFTDx documentation: https://docs.nvidia.com/cuda/cufftdx/
- NVIDIA MathDx download: https://developer.nvidia.com/mathdx-downloads
- NVIDIA CUDA Toolkit documentation: https://docs.nvidia.com/cuda/
- 3GPP TS 38.211 - Physical channels and modulation (PRACH sequence definition).
- 3GPP TS 38.213 - Physical layer procedures for control (PRACH procedure).