Intel ACC100 - LDPC offload
8 minute read
Highlights
- LDPC offload for both PDSCH and PUSCH the most CPU-heavy channel-coding steps move off the host and onto the accelerator.
- Configuration-driven enable or disable via the DU YAML; no code changes.
- Multi-VF scaling allowlisting additional ACC100 VFs automatically spreads load across them.
- Unified metrics the same per-block PHY metric fields populate whether LDPC runs in software (AVX-512) or on the accelerator, enabling direct side-by-side comparison from one log format.
- Measured gains on real traffic significantly lower PUSCH decode latency, tighter tail latency, higher processor throughput, and reduced upper-PHY uplink CPU (see Section 7).
1. Prerequisites
1.1 Hardware
- Intel ACC100 PCIe card, SR-IOV capable; at least one VF exposed to the host.
- x86-64 CPU with AVX2 (AVX-512 recommended for the software-fallback path).
- ≥ 2 GB of 2 MiB hugepages.
- PCIe slot on the same NUMA node as the upper-PHY worker cores.
1.2 Software
| Component | Minimum version | Notes |
|---|---|---|
| DPDK | 22.11 | Tested with 25.11; ACC100 PMD (baseband_acc) required. |
| Linux kernel | 5.15+ | IOMMU enabled (intel_iommu=on iommu=pt). |
pf_bb_config |
24.03+ | PF configurator daemon; must run continuously. |
| DU build flags | ENABLE_DPDK=True, ENABLE_PDSCH_HWACC=True, ENABLE_PUSCH_HWACC=True |
See Section 5. |
1.3 Kernel and VFIO setup
# Kernel boot parameters (then update-grub + reboot):
intel_iommu=on iommu=pt hugepagesz=2M hugepages=1024
# Hugepage mount if not done by distro:
echo 1024 | sudo tee /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
# Load VFIO modules:
sudo modprobe vfio-pci
echo 1 | sudo tee /sys/module/vfio_pci/parameters/enable_sriov # if kernel-builtin
# Create one SR-IOV VF and bind it to vfio-pci:
echo 1 | sudo tee /sys/bus/pci/devices/<ACC100_PF_BDF>/sriov_numvfs
sudo dpdk-devbind.py --bind=vfio-pci <ACC100_VF_BDF>
# Start pf_bb_config holding the PF group open with a VF token.
# The token (UUID) is required in the DU's EAL args.
sudo /opt/pf-bb-config/pf_bb_config ACC100 \
-c /opt/pf-bb-config/acc100/acc100_config_vf_5g.cfg \
-v <UUID> &
After setup, dpdk-test-bbdev should enumerate the VF as intel_acc100_vf.
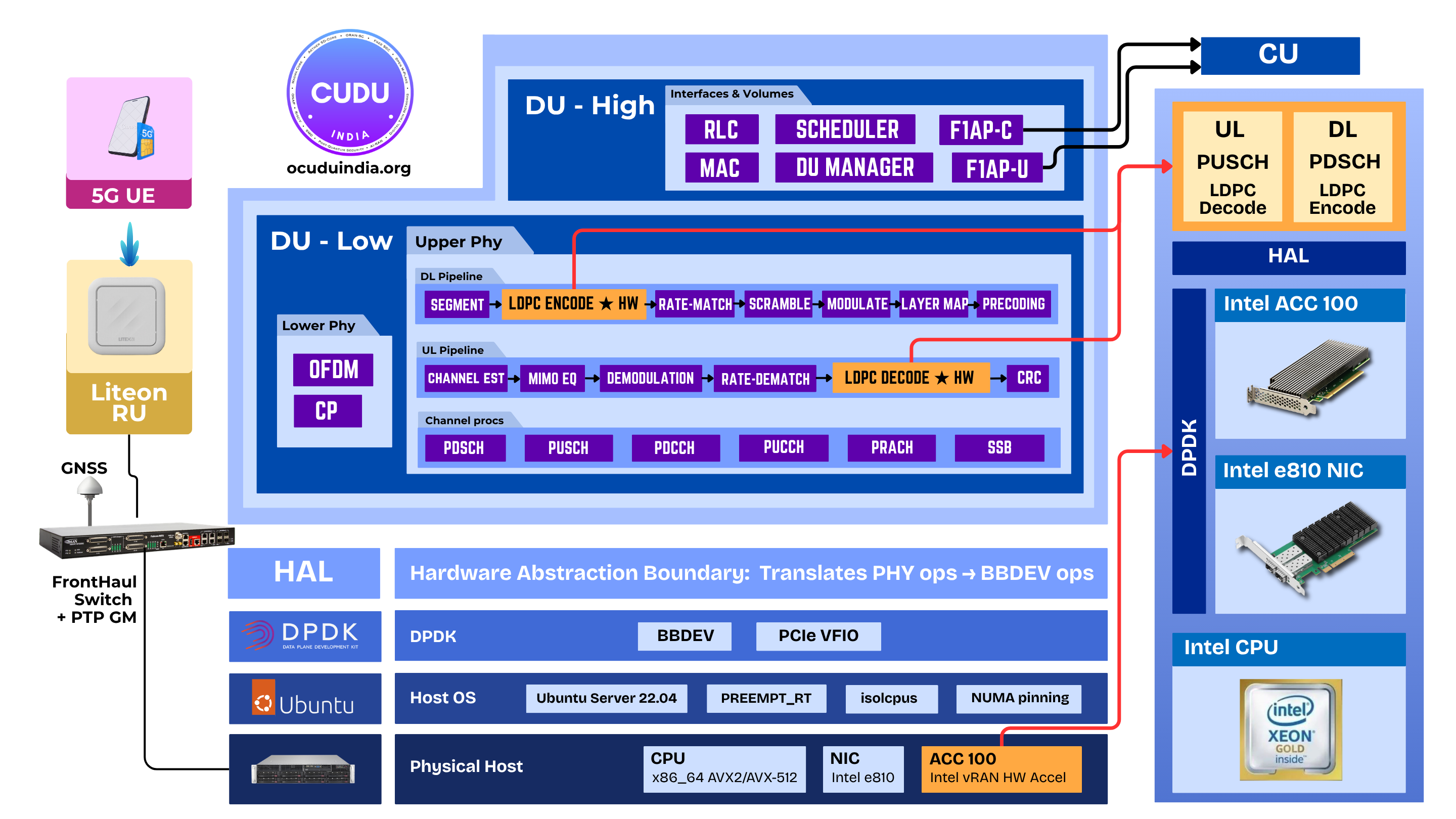
2. Architecture overview
2.1 Where LDPC sits in the upper-PHY
LDPC encode (PDSCH) and LDPC decode (PUSCH) are the two steps this feature accelerates. On the software path they are AVX2/AVX-512 kernels; on the HW path they become batched DPDK BBDEV operations dispatched to the ACC100. Everything else in the chain stays on the CPU.
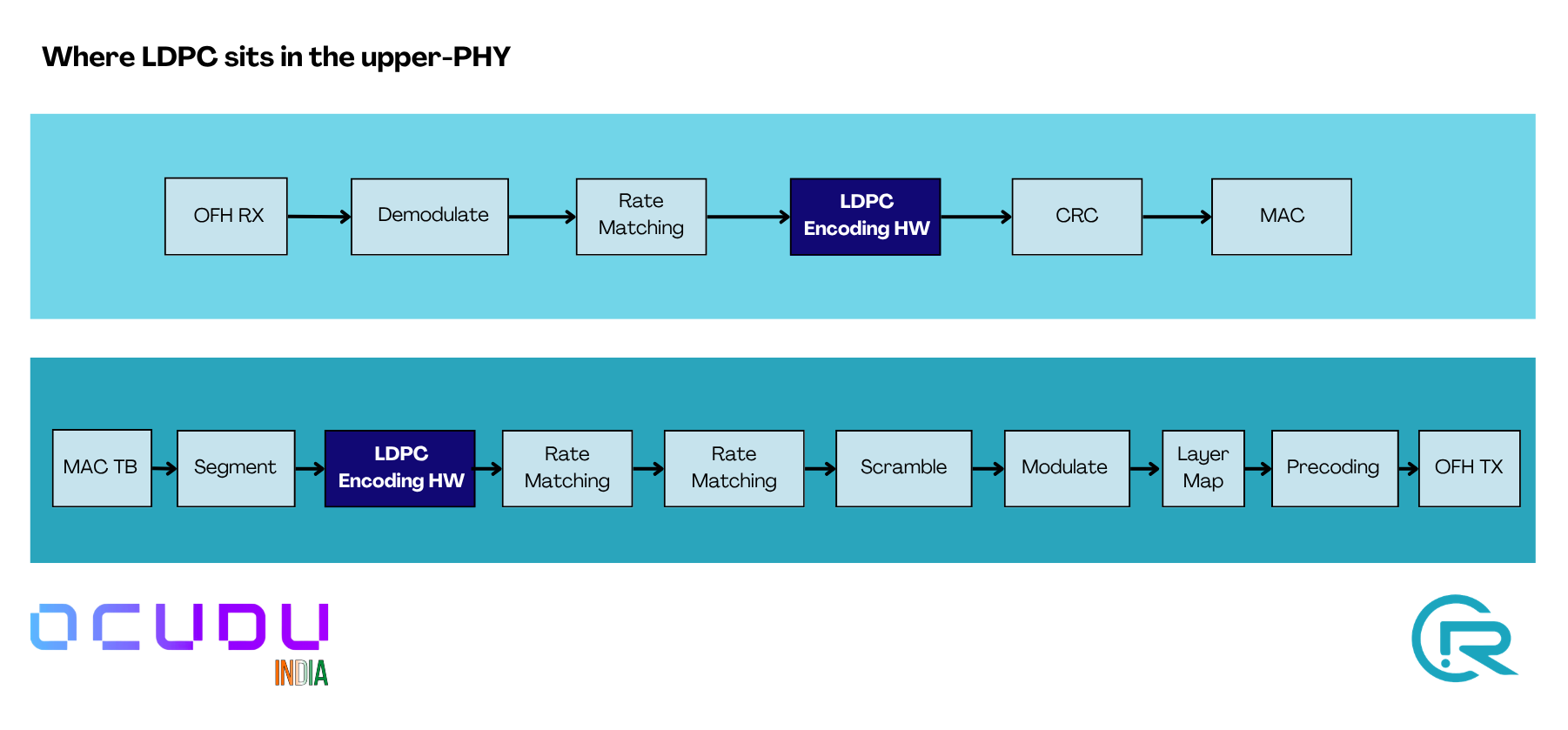
2.2 HAL layering
The upper-PHY factory checks for a hardware accelerator factory at construction. If present, the HW path is built; otherwise the software AVX-512 path is used. The choice is made once at startup from the YAML there is no runtime toggling.
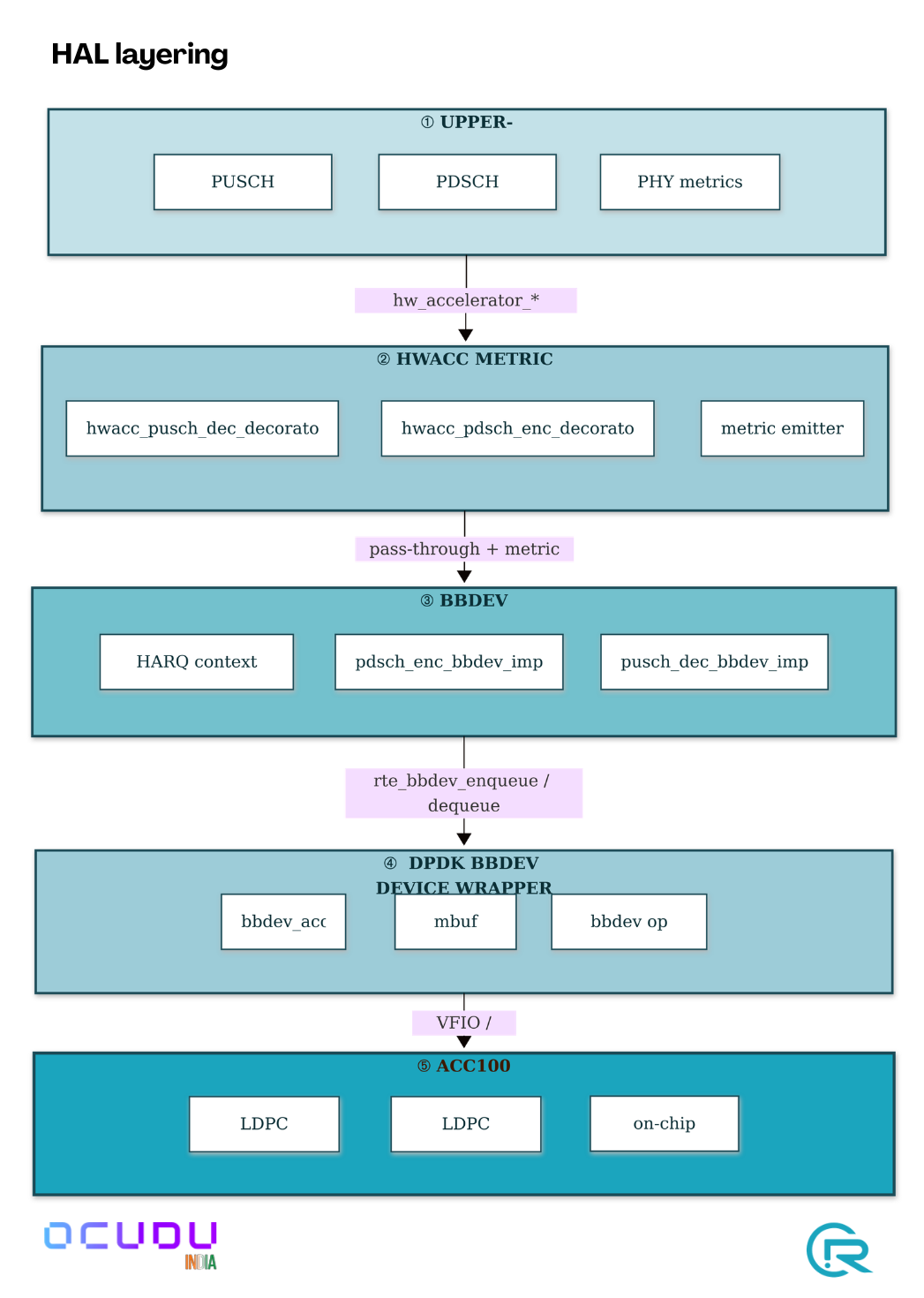
3. Implementation summary
The integration is implemented as a hardware-abstraction layer that plugs into the existing upper-PHY factory pattern. Four things are worth knowing:
-
Batching. Encode and decode ops are accumulated in a per-instance buffer and submitted to the accelerator as a single burst on the first dequeue call of each transport block. This amortises the DPDK per-call cost across all code blocks of the TB.
-
Shared pools. The HAL factory owns one set of DPDK mbuf and op mempools for all encoder and decoder instances the upper-PHY creates. Pool size scales automatically with the total queue count across allowlisted accelerators.
-
On-chip HARQ. Soft data for HARQ combining stays on the accelerator between transmissions, addressed by a CB-indexed offset. The host tracks only the lifecycle of each context entry, not the soft data itself.
-
Unified metrics. A thin decorator wraps the HW accelerator interface, times each enqueue–dequeue pair, and emits the same metric events the software path does. The existing upper-PHY aggregator consumes both sources transparently.
A handful of ACC100 silicon quirks are handled internally by the HAL (input byte-alignment, a single-CB transport-block special case, a per-op E-limit guard, a long-session HARQ-context wrap-around). These require no action from the operator.
4. Configuration
Enable ACC100 offload in the DU YAML:
hal:
eal_args: "--lcores (0-1)@(0-17) --file-prefix=ocudu_gnb --no-telemetry
-a <OFH_NIC_VF_BDF>
-a <ACC100_VF_BDF>
--vfio-vf-token=<PF_BB_CONFIG_UUID>
--iova-mode=pa"
bbdev_hwacc:
hwacc_type: "acc100"
id: 0
pdsch_enc:
nof_hwacc: 4
cb_mode: true
dedicated_queue: true
pusch_dec:
nof_hwacc: 4
force_local_harq: false
dedicated_queue: true
Notes:
nof_hwaccfor single-cell deployments, 2–4 is sufficient; for multi-cell or heavy-load setups, 8–16. Setting higher than the upper-PHY’s concurrency limits is wasteful.--iova-mode=pais recommended; thevamode is known to interact poorly with some NIC drivers in DPDK 25.11.- The VFIO-VF token must match the UUID passed to
pf_bb_config -v. Ifpf_bb_configis restarted, update the YAML.
5. Build guide
5.1 gNB with 7.2 fronthaul and ACC100 offload
cd ~/ocudu
mkdir -p build_hwacc && cd build_hwacc
sudo cmake -DDU_SPLIT_TYPE=SPLIT_7_2 \
-DENABLE_DPDK=True \
-DENABLE_PDSCH_HWACC=True \
-DENABLE_PUSCH_HWACC=True \
-DASSERT_LEVEL=MINIMAL \
../
sudo make -j$(nproc)
Binary: build_hwacc/apps/gnb/gnb.
5.2 Benchmarks
cd build_hwacc
sudo make -j$(nproc) pdsch_processor_benchmark pusch_processor_benchmark
5.3 Startup verification
When the DU starts with ACC100 configured, the log should contain:
[HWACC] [I] [bbdev] dev=0 driver=intel_acc100_vf ...
[HWACC] [I] [bbdev] dev=0 started: ldpc_enc_q=N ldpc_dec_q=N ...
and on stdout:
Warning: the configured maximum PDSCH concurrency ... is overridden by the
number of PDSCH encoder hardware accelerated functions (N)
Warning: the configured maximum PUSCH and SRS concurrency ... is overridden
by the number of PUSCH decoder hardware accelerated functions (N)
6. Metrics
Enable the upper-PHY metric block in the YAML:
metrics:
enable_log: true
enable_verbose: true
layers:
enable_du_low: true
periodicity:
du_report_period: 1000
Every second the log will include a block similar to:
LDPC Encoder: avg_cb_size=... bits, avg_latency=... us, encode_rate=... Mbps
LDPC Decoder: avg_cb_size=... bits, avg_latency=... us, avg_nof_iter=..., decode_rate=... Mbps
...
CPU usage: upper_phy_dl=...%, ldpc_enc=...%, ...
upper_phy_ul=...%, ldpc_dec=...%, ...
The same fields populate for both the CPU-software and ACC100-HW paths, enabling side-by-side A/B comparison from a single log format.
7. Results
7.1 Test environment
| Item | Value |
|---|---|
| Host | Single-socket x86_64, 18 cores, AVX-512 capable |
| OS / DPDK | Linux 5.15 / DPDK 25.11 |
pf_bb_config |
24.03 |
| ACC100 | 1 PF + 1 VF bound to vfio-pci |
| OFH NIC | iavf VF for 7.2-split RU |
| UE workload | Real UE + iperf3 DL/UL + 2 min video streaming + 2 speed tests |
| Cell | 100 MHz TDD, 30 kHz SCS, 4T4R, band n78, 256-QAM max |
All measurements taken with the same physical UE and RU; only the gNB binary differs between the two rows (AVX-512 vs ACC100).
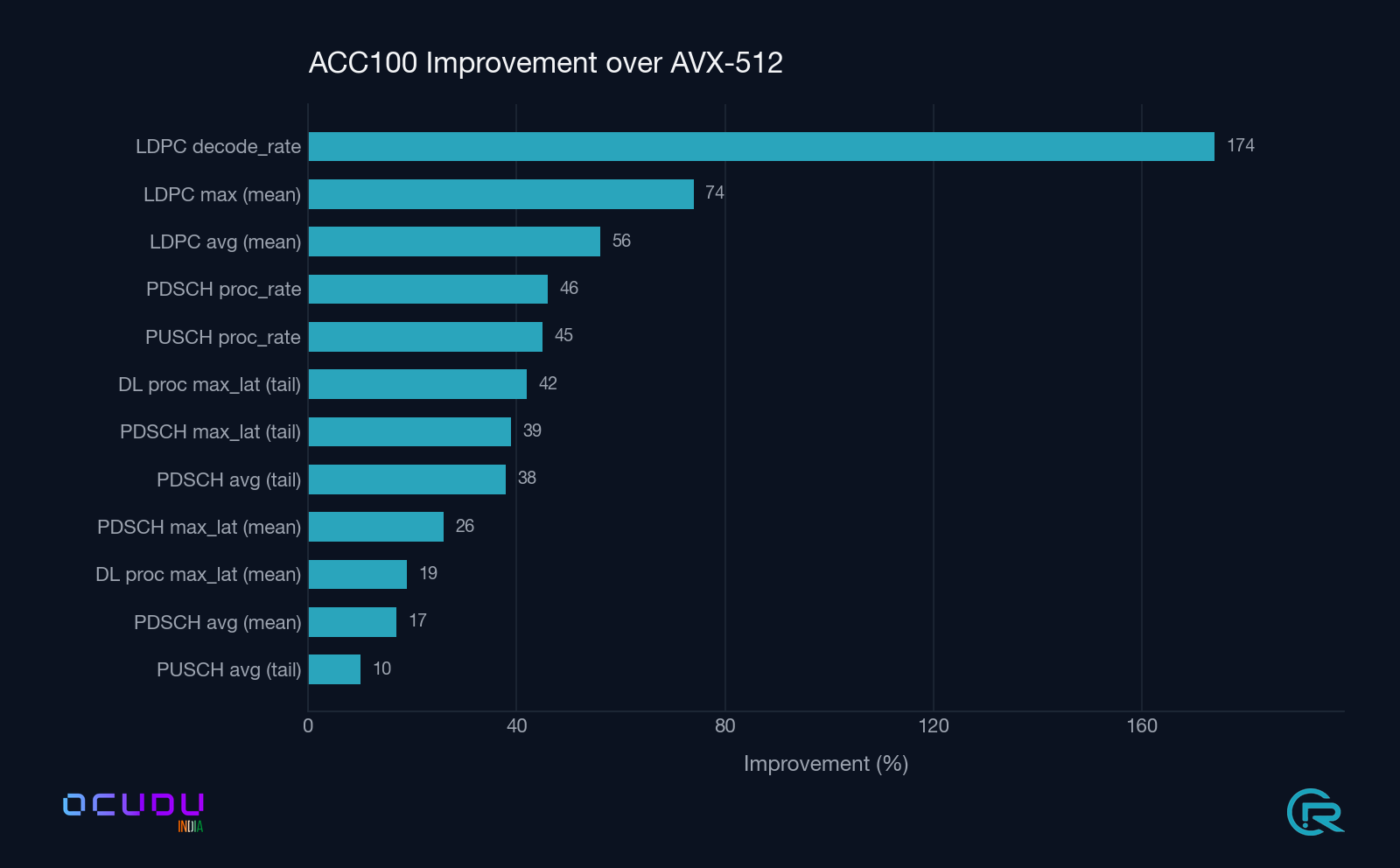
7.2 End-to-end upper-PHY A/B
Mean / max over ~175 one-second metric windows each.
| Metric | AVX-512 (mean / max) | ACC100 (mean / max) | ACC100 Δ |
|---|---|---|---|
DL processing max_latency |
114.9 / 330.2 µs | 99.7 / 206.4 µs | −13 % mean, −37 % tail |
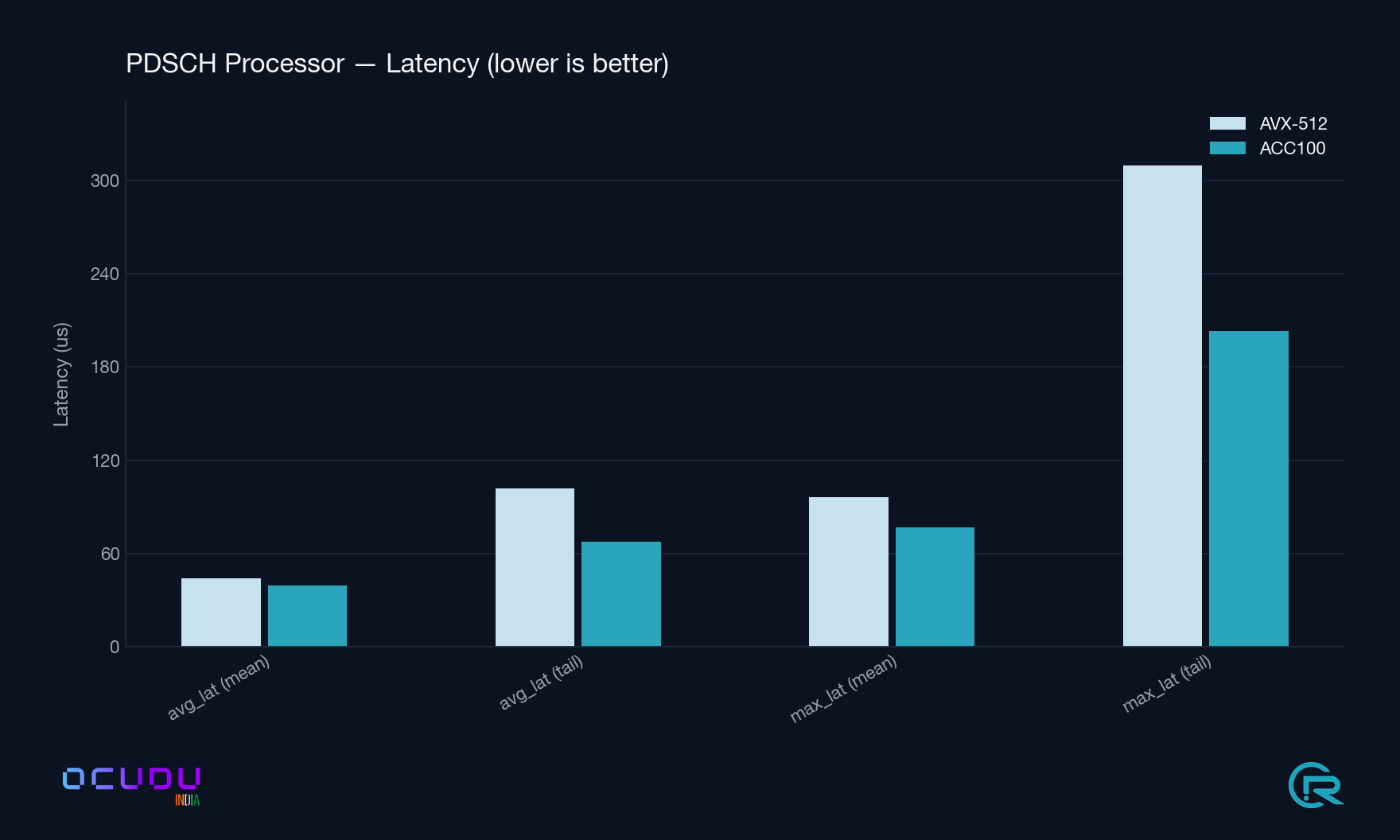
PDSCH Processor avg_latency |
44.0 / 101.7 µs | 39.3 / 67.8 µs | −11 % mean, −33 % tail |
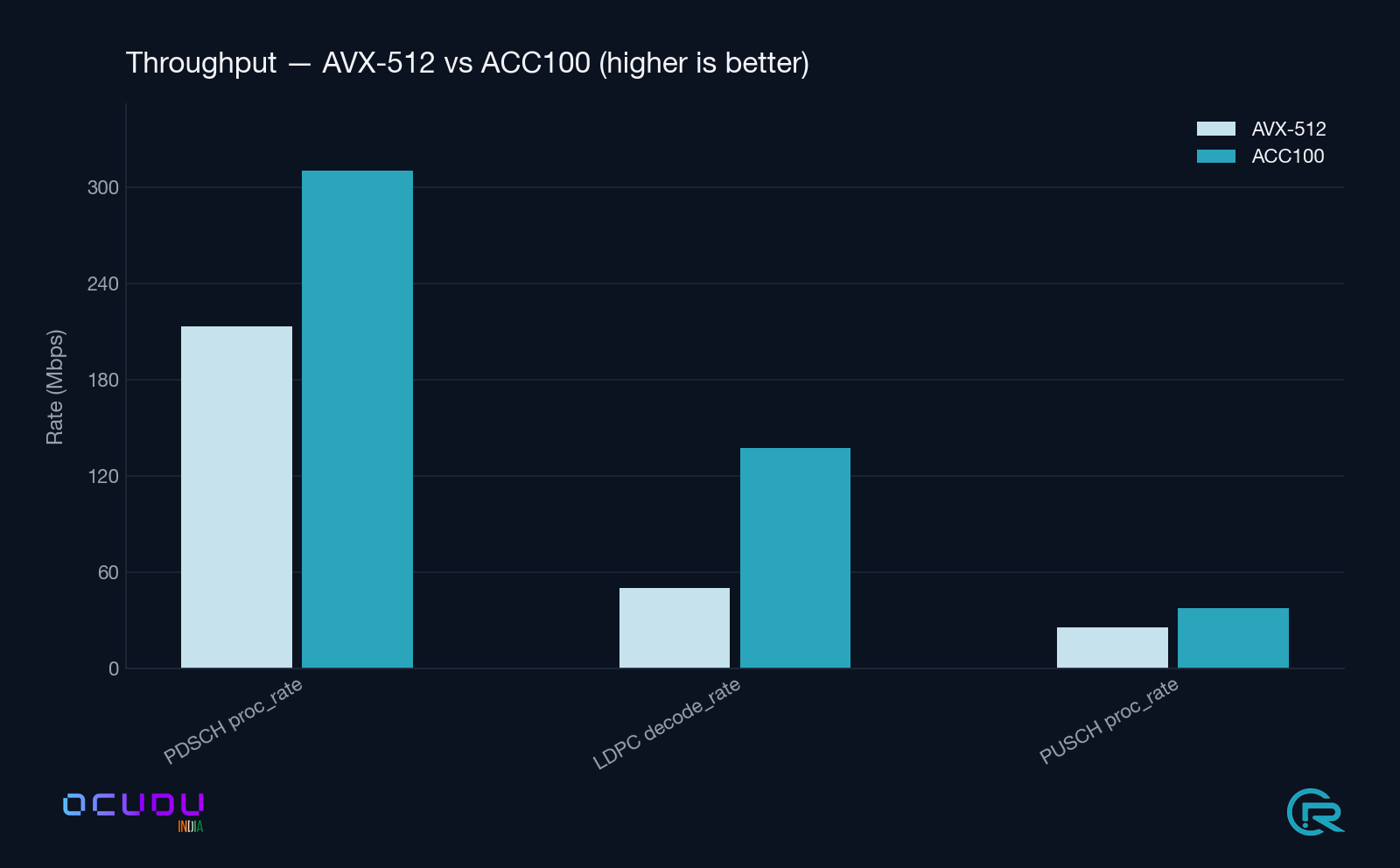
PDSCH Processor proc_rate |
198.0 Mbps | 310.1 Mbps | +57 % |
PDSCH Processor max_latency |
96.5 / 309.8 µs | 76.6 / 203.2 µs | −21 % mean, −34 % tail |
LDPC Decoder avg_latency |
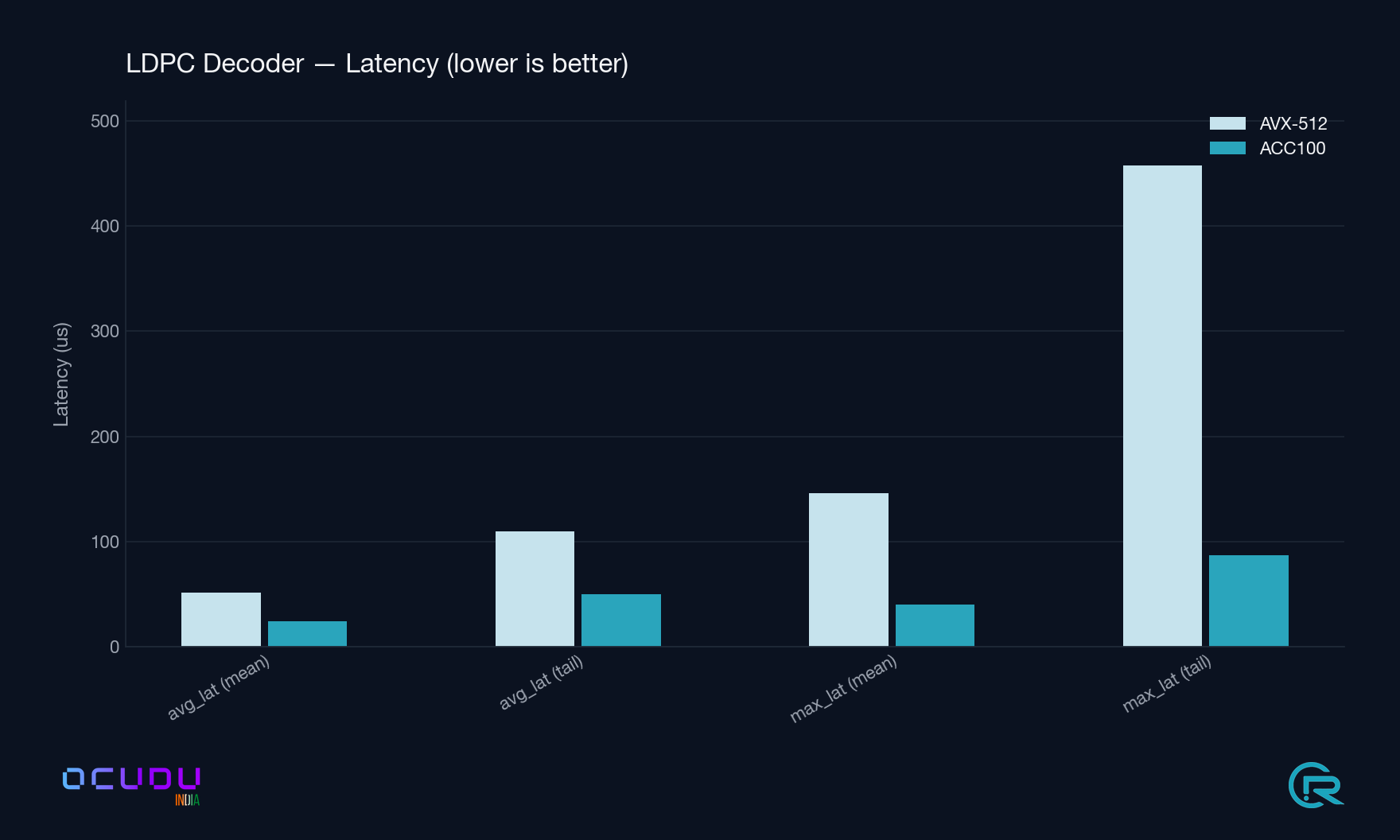
51.6 / 109.4 µs | 24.5 / 50.1 µs | −53 % (2.1× faster) |
LDPC Decoder max_latency |
145.9 / 457.7 µs | 40.5 / 86.7 µs | −72 % (3.6× better tails) |
LDPC Decoder decode_rate |
46.6 Mbps | 137.4 Mbps | +195 % (2.9×) |
PUSCH Processor avg_data_latency |
231.9 / 761.5 µs | 246.3 / 736.4 µs | +6 % mean, −3 % tail |
PUSCH Processor proc_rate |
24.0 Mbps | 37.4 Mbps | +56 % |
7.3 CPU utilisation
| Metric | AVX-512 (mean / max) | ACC100 (mean / max) |
|---|---|---|
upper_phy_dl |
3.63 % / 22.7 % | 4.92 % / 33.9 % |
upper_phy_ul |
3.79 % / 28.9 % | 2.36 % / 15.4 % (−38 %) |
ldpc_rm (rate match) |
1.30 % / 10.9 % | 0.00 % (on accelerator) |
ldpc_rdm (rate dematch) |
0.13 % / 1.0 % | 0.00 % (on accelerator) |
The uplink CPU reduction is the headline operational benefit: one core is freed on the upper-PHY under sustained traffic, allowing either higher cell counts on the same host or tighter scheduling-latency budgets.
Note on the DL rows. The per-CB
ldpc_encoder_*fields on the HW path reflect batch wall-clock time rather than serialised per-CB compute time, because ops are submitted to the accelerator in bursts. Use the PDSCH Processor rows andupper_phy_dlfor apples-to-apples DL comparison - those are measured once per TB and are directly comparable.
8. Deployment checklist
- Install or confirm DPDK ≥ 22.11 with ACC100 PMD.
- Confirm
pf_bb_configdaemon is running; note its VFIO-VF token. - Bind the ACC100 VF(s) to
vfio-pci. - Add the
hal.bbdev_hwaccblock to the DU YAML (see Section 4). - Build with
ENABLE_PDSCH_HWACC=TrueandENABLE_PUSCH_HWACC=True(see Section 5). - Verify startup log shows
intel_acc100_vfandldpc_enc_q=N ldpc_dec_q=N. - Enable
metrics.layers.enable_du_lowto observe the per-component LDPC metrics (Section 6).
9. References
- DPDK BBDEV programmer’s guide: https://doc.dpdk.org/guides-25.11/prog_guide/bbdev.html
- Intel
pf_bb_config: https://github.com/intel/pf-bb-config - 3GPP TS 38.212 Multiplexing and channel coding.