
3 minute read
Modern vRAN systems are steadily transitioning toward heterogeneous compute architectures, where general-purpose CPUs are augmented with domain-specific accelerators to meet strict real-time PHY requirements.
Among all PHY functions, LDPC (Low-Density Parity-Check) channel coding stands out as one of the most compute-intensive and latency-sensitive operations - directly impacting both throughput and system efficiency.
To address this, OCUDU extends its upper-PHY pipeline with hardware-accelerated LDPC support using a BBDEV-based execution model, enabling seamless integration with external FEC accelerators such as Intel ACC100.
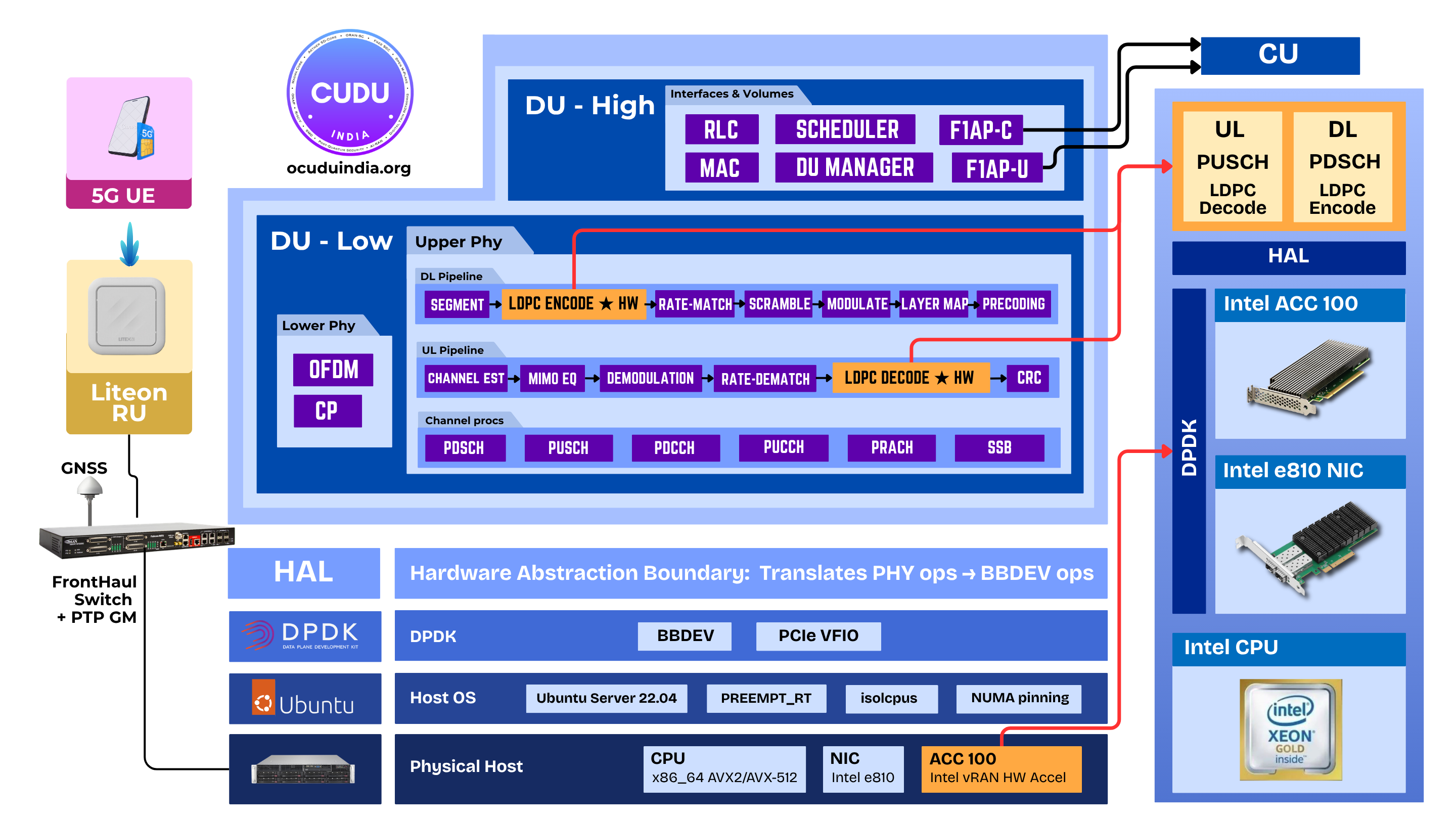
Architecture Overview
The integration builds on OCUDU Ecosystem Foundation modular upper-PHY design, with a strict separation between execution logic and backend implementation.
Core Design Principles
- Hardware Abstraction Layer (HAL) Defines a uniform interface for LDPC encode/decode operations
- Runtime Backend Selection Upper-PHY dynamically selects execution path (software vs hardware)
- Unified Observability Layer Ensures identical metrics across all execution paths
Execution Pipeline
At runtime, LDPC operations follow a consistent and backend-agnostic pipeline:
- Request Generation Encode (PDSCH) and decode (PUSCH) operations originate in upper-PHY
- Descriptor Translation Requests are mapped into BBDEV-compatible descriptors
- Batching & Enqueue Operations are grouped and submitted to the accelerator
- Asynchronous Processing Accelerator processes LDPC code blocks independently
- Completion & Reintegration Results are dequeued, validated (CRC/iterations), and reintegrated into the PHY pipeline
This invariant execution model ensures no changes are required in higher layers, regardless of backend.
Implementation Highlights
LDPC Offload Path
- Full support for LDPC encode and decode via BBDEV
- Descriptor construction aligned with accelerator requirements
- Support for iterative decoding and early termination
HARQ Integration
- Utilizes on-chip HARQ memory for offloaded flows
- Code-block indexed addressing eliminates host-side buffer overhead
Parallelism & Scaling
- Multi-VF scaling distributes workload across accelerator instances
- Round-robin dispatch avoids queue bottlenecks
- Batched enqueue/dequeue reduces MMIO overhead and improves throughput
Runtime Flexibility
- Backend selection via configuration (YAML-driven)
- Single binary supports software and hardware LDPC paths
This enables true A/B benchmarking under identical runtime conditions.
Observability
A key design goal was metric symmetry:
Hardware and software paths emit identical counters:
ldpc_enc_*,ldpc_dec_*- Latency, throughput, iteration count, CRC status
No changes are required for:
- Dashboards
- Logging pipelines
- Benchmarking frameworks
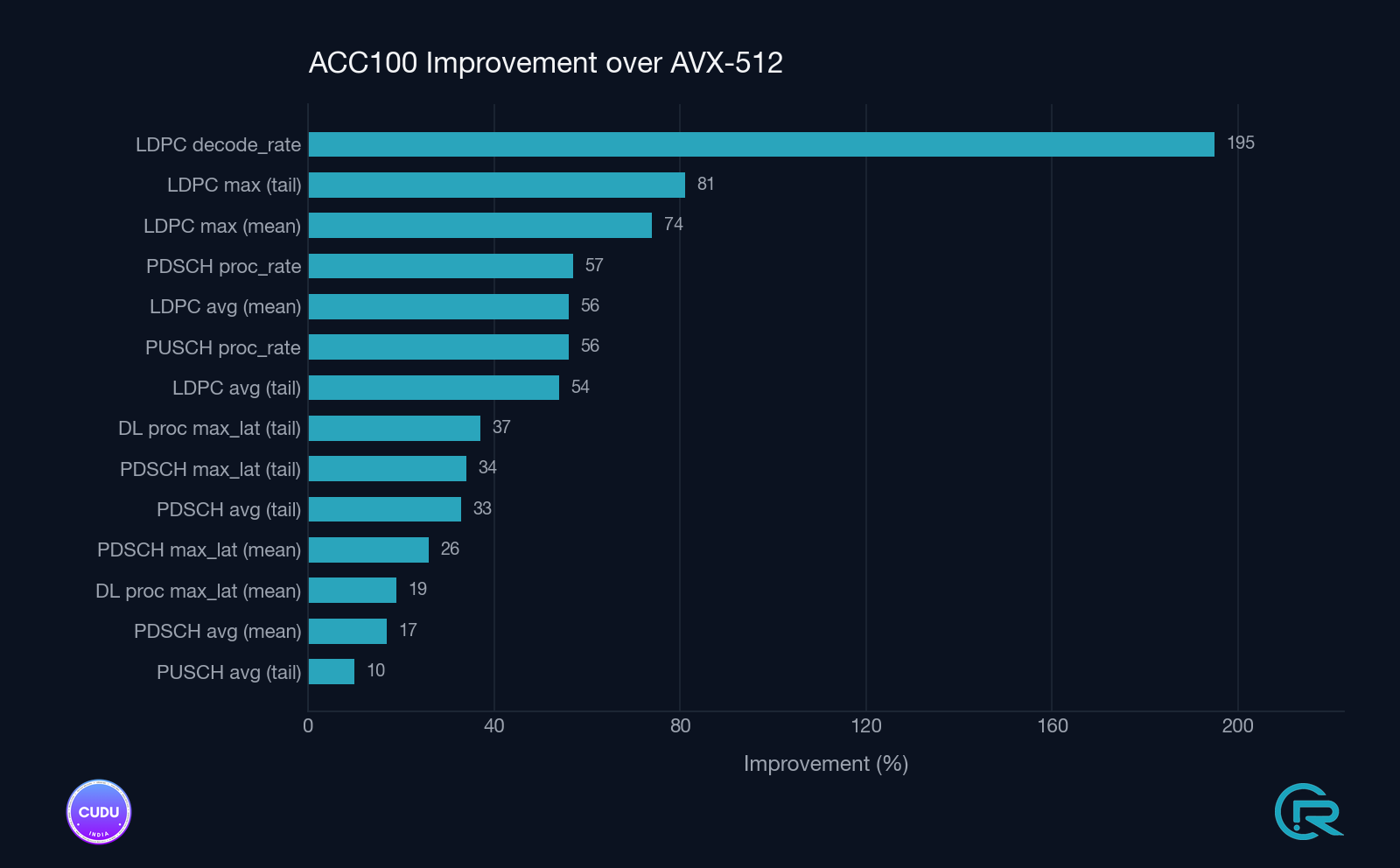
Measured Impact
Validation was conducted on a 100 MHz TDD cell, using a real UE over a 7.2-split RU architecture, with all parameters held constant except the LDPC backend.
Observed Improvements
- Rate Match/Dematch: Fully offloaded
- LDPC Decode Rate: ~2.9× improvement
- Uplink Upper-PHY CPU Utilization: ~38% reduction (~1 core freed)
- PDSCH Throughput: ~57% increase
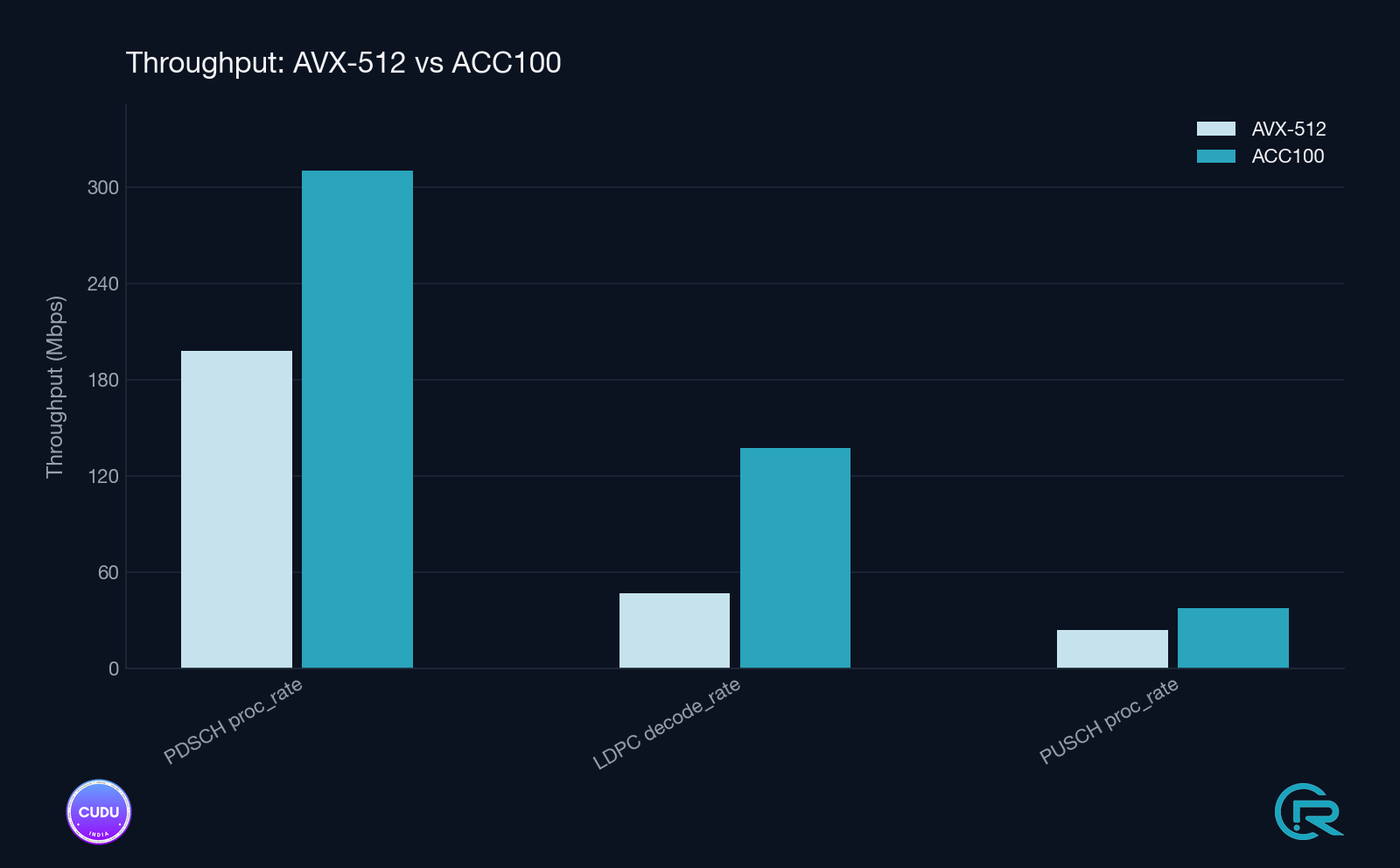
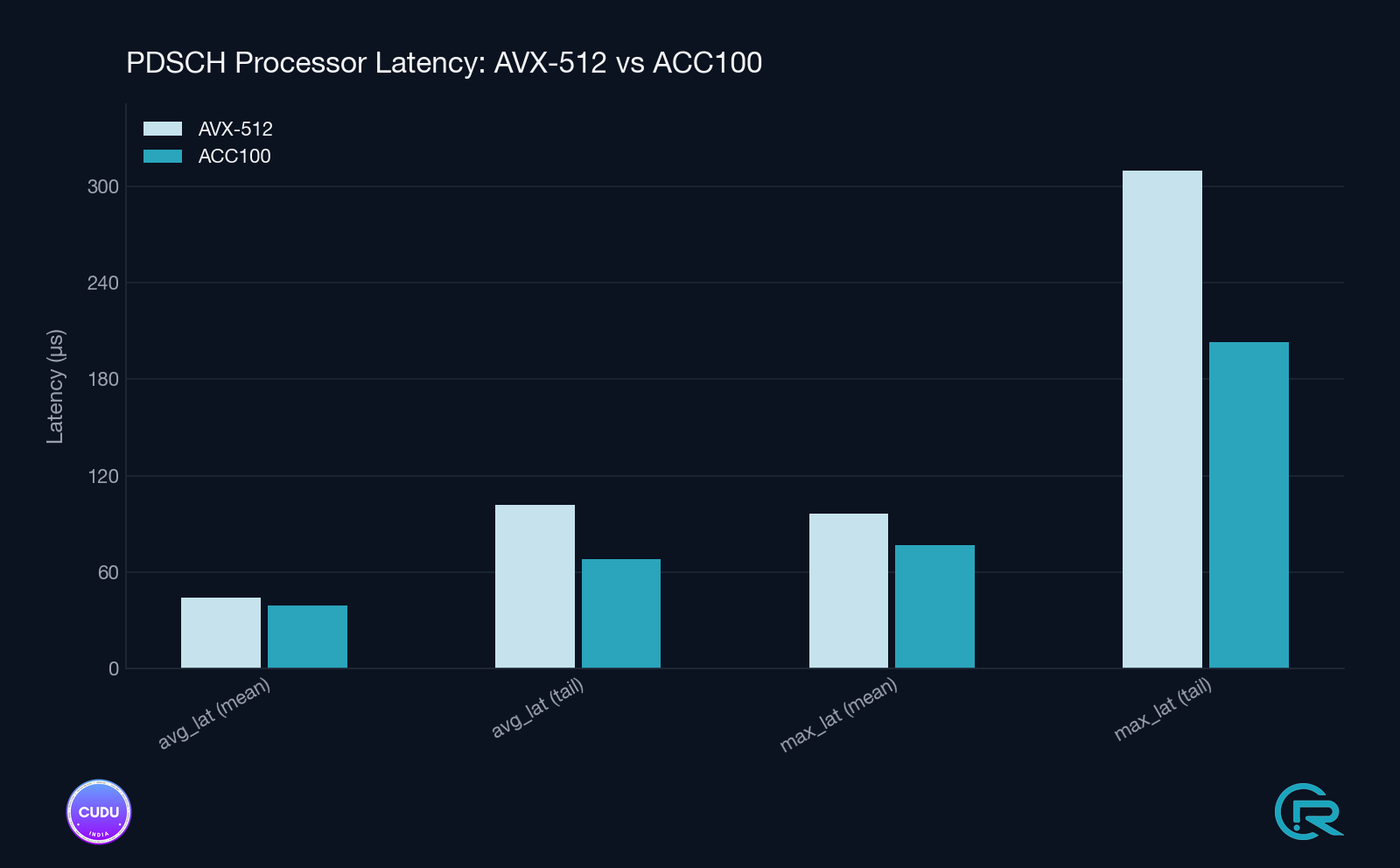
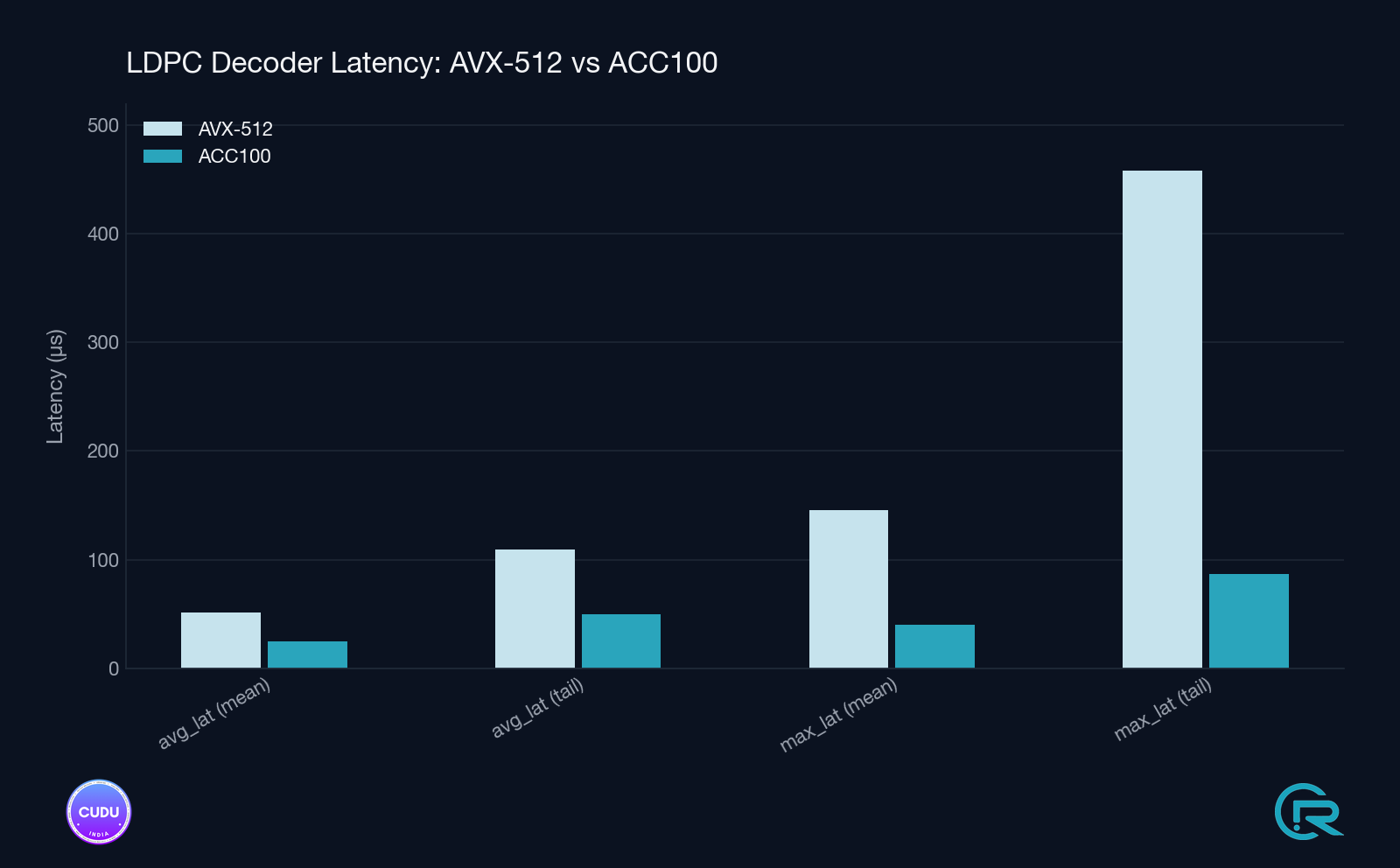
Why This Matters
This implementation goes beyond raw acceleration - it introduces a portable and extensible execution framework.
Key advantages:
- Decouples PHY logic from hardware specifics
- Enables plug-and-play accelerator integration
- Preserves software consistency and observability
- Supports future backends, including custom silicon
Availability
- Codebase: github.com/OCUDU-India/OCUDU (branch: hwacc_acc100)
- Documentation: docs.ocuduindia.org → Intel ACC100 (LDPC)
Closing Thoughts
With BBDEV-based LDPC offload, OCUDU takes a significant step toward becoming a truly accelerator-aware vRAN stack - capable of scaling across evolving hardware ecosystems while maintaining architectural consistency.
As next-generation accelerators and custom silicon continue to emerge, this design lays a strong foundation for future-ready, high-performance Open RAN deployments.